




任佳伟:使用「Web Scraper」抓取商品信息

之前我们讲到用Chrome插件——Instant Data Scraper来爬取亚马逊的Review,许多小伙伴已经不再满足于爬Review了。怎么办?那就要学习更厉害的工具啦,当然更厉害的工具也会更复杂。
今天要为大家介绍的也是一个Chrome插件——Web Scraper。看看它在「Chrome应用商店」的评价吧,我相信它也会给你惊喜的!

有的小伙伴可能会说,你之前不说去你的「Web Scraper!」吗?

哎呀,我就那么一说嘛。毕竟我们连亚马逊都敢做,学习怎么用一个爬虫插件有难度?不存在的!那么就我开始学习使用「Web Scraper」吧!
一到底怎么添加Chrome插件?
方式1:
访问https://chrome.google.com/webstore
(需要科学上网),在页面搜索「Web Scraper」,搜索结果正第一个就是啦,点击按钮「添加至CHROME」。
方式2:
直接百度搜索「Chrome插件」找一些非Google官方的网站下载插件。点击按钮「添加至CHROME」。
方式3:
如果小主你实在找不到,私信我吧。
成功安装后你的浏览器右上角会显示

这个蜘蛛网图标。
二如何使用Web Scraper?
1、打开Web Scraper
装好插件后是不是迫不及待试试看它能帮我抓到什么数据?那我们就一起来爬亚马逊的商品吧。
这里我选择的爬美国站Best-Sellers中的Book,打开链接后按下F12或在网页空白处点击鼠标右键—>检查。什么鬼!浏览器出现了一堆看不懂的东西?不用担心,再点击↓

这就到「Web Scraper」的界面了。
2、创建爬虫
如图点击Create new sitemap → Create Sitemap
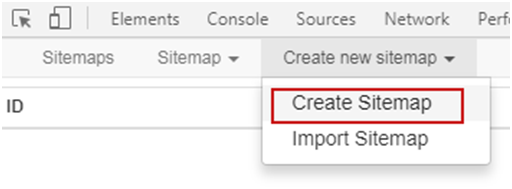
在Sitemap name中填入自己想要为这个爬虫取的名字,如:「book」。在Start URL中填写想要爬的网站链接,这里我们填入亚马逊Best Sellers in Books的链接:https://www.amazon.com/best-sellers-books-Amazon/zgbs/books/ref=pd_dp_ts_books_1,点击「Create Sitemap」就创建了一个名为「Book」的爬虫。
3、创建选择器
完成爬虫的创建后我们就需要创建选择器了,选择器我们可以认为它是你需要爬取的范围。点击「Add new selector」,将跳转至这个页面。
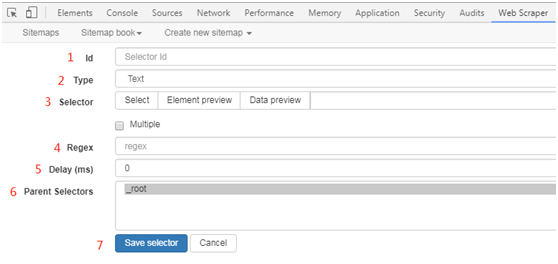
「id」(即给选择器命名)我们可以自由发挥,只要你自己知道这个「ID」代表的是这个选择器(爬取范围)就OK啦!这里我们先爬取商品的标题,所以命名为title。
「Type」选择的是类型,这里我们默认为「Text」类型。
三「Selector」
「Selector」就是这里的重点了!

1、我们首先点击Selector中的「Select」按钮,将鼠标移动到页面上。你会发现你的鼠标所到之处都会变成「原谅色」(绿色),这就对了。我们将鼠标移动到一本书的标题上,标题底色变红,就表示已经选取了这一本书的标题,如下图↓
别停再点旁边另一本书的名字。这样做的目的是为了让「Web Scraper」找到当前页面中所有相同属性的数据,一般情况下点击两个数据,该页面所有相同数据底色都会变红。
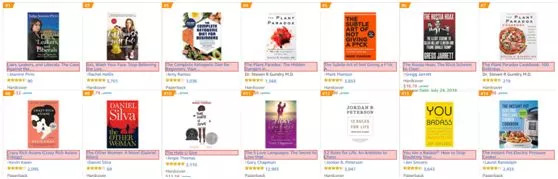
2、「Element preview」按钮可预览当前已选择的元素,点击后效果与上图一样。
3、「Data preview」按钮可预览当前已抓取到的数据。可我们完成上面步骤后点击「Data preview」却仅有一条数据是为啥?

看到「Multiple」没有?点一下,再按「Data preview」按钮就可以看到整页所有书籍的标题啦。
「Regex」意思是正则表达式,在这里我们默认不填。正则表达式是一个用来匹配字符串的一个模式,最简单的正则表达式就是一个简单的字符串,比如'python'这个可以用来匹配'python'这个词语。你可以用正则表达式在一串字符中来匹配一个你要查找的内容,或者替换他,或者将其分割成字符片段。对于正则表达式,以为IT大牛James Werner Zawinski曾经用“some people, when confronted with a problem, think, "I know, I'll use regular expressions." Now they have two problems.”这句话来形容正则的晦涩、难懂。
「Delay」表示每次访问中的延迟时间,这里我们设置为500。
「Parent Selectors」会罗列出各选择器的层级关系。
「Save Selector」点击该按钮可以保存选择器。
4、数据抓取和保存,在完成选择器编辑并预览数据无误后,我们就可以设置爬取参数并开始抓取数据了。
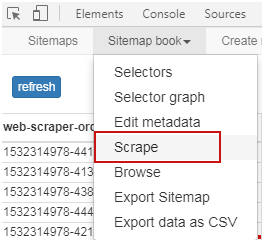
如图点击「Scrape」会转至爬取参数界面。
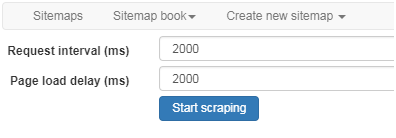
其中「Request interval」指每次请求间隔、「Page load delay」指每次页面加载延时。这两个参数都不建议设置过小,若过快页面会出现验证码,导致我们无法抓到想要的数据。完成参数填写后点击「Start scraping」就开始爬取数据啦!
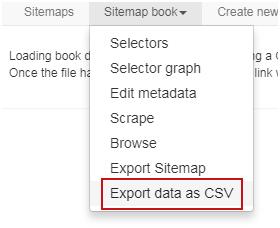
在完成爬取后,点击「Export data as CSV」就可以把数据以CSV格式保存到本地啦。至此大功告成!
今天是「Web Scraper」最最最基础的教程,因为很多新手卖家反馈说复杂的看不太懂。大家有什么问题或者想看什么类型的干货都可以留言,这边会一一回复你们!





")




















