


亚马逊最有价值的新功能——A/B Test主图拆分测试(8000字深度长文)

 24718
24718
目录
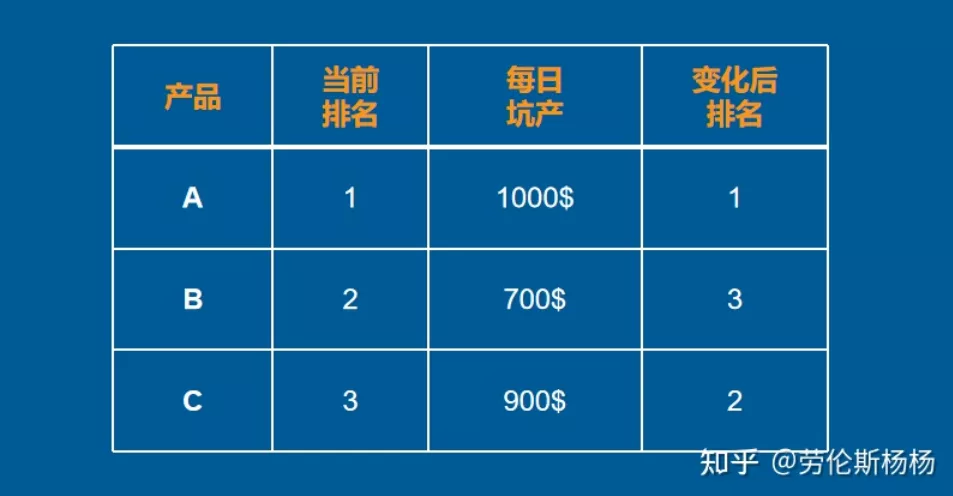
坑产该如何计算呢?

影响曝光的是关键词排名,如果其他因素指标没问题的话,好的产品会进入“关键词排名提高——曝光增大——坑产GMV增加——关键词排名进一步提高”的良性循环,直到你前面挡着一个比你各方面指标更优的产品;
我们常说的转化率越高,自然排名越高,这个逻辑是没问题的,但转化率只是关键词排名众多影响因素的其中一个因素;
点击率很重要,它会直接影响有多少流量进入你的详情页面,否则转化率再高,产品也会陷入到无米下锅的尴尬境地;
客单价的影响也不容小觑,某些类目下高低客单产品共存时,高客单在推排名方面会有些优势,有时卖一个产品等于低客单卖10个,虽说高客单价的转化也会低一些,只要不是标品类目,转化率总不至于比别人低10倍吧。同样的,如果两个产品每日出单相同,其中高客单的产品由于能带来更多的GMV,其在BSR排名和关键词排名下都会更靠前一些。
Tips:假设两个产品的坑产GMV完全相同,但是客单价一个高一个低,亚马逊会让谁的排名在前面呢?
转化率高的产品排名更靠前,因为转化率高说明满足了更多人的需求,照顾到了更多人的购物体验,这样更符合亚马逊以客户为中心的价值观。由于此时坑产GMV相同,高客单价产品一定是转化低的,所以高转化的低客单产品排名会更靠前。例如下图:
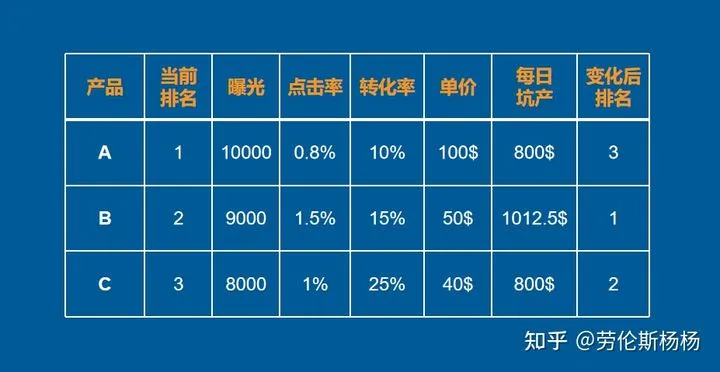
主图
标题
价格
Review
FBA
折扣力度
Deals标志
配送时间
BS或AC标

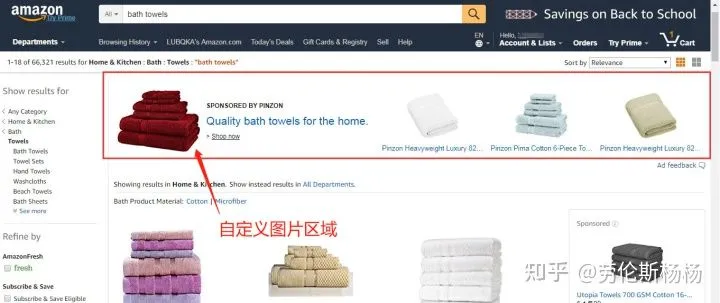
选择两张要进行对比测试的产品主图分别放在两个新开SB广告中,
选择一个流量比较大的关键词
用精准匹配
保持竞价相同
投放相同的一段时间
保证两组广告的曝光都大于4000
两组广告必须都是新开的,防止因为其中一组广告存在历史积累权重影响实验结果;
选择大流量词是为了尽快积累足够多数据,防止测试花费太长时间;
选精准匹配是为了确保流量来源一致的,因为不同的关键词往往代表的是不同需求,对产品图片的好恶也会存在差异;
竞价相同倒不是因为担心广告展示的位置不同,(记得那时头条广告还只展示在搜索结果头部位置)单纯是为了确保两组广告初始条件一致;
投放时间段一致是为了确保排除掉极端情况的出现(例如旺季和淡季广告的效果也会有差异性)
曝光大于4000是我人为设置的一个节点,防止数据样本过少,导致结果出现偶然性,虽然数据越多结果肯定越准确,但还要考虑测试的成本,综合下来,我认为4000的曝光量已足以完成实验;
实验缺陷:
2. 数据量:
即使我们设置了相同的竞价,相同的预算,但有时就是会出现一个广告组数据贼多,另一个却一直跑不出什么数据的情况,到了实验规定的截至日期之后(由于实验会产生时间和金钱成本,所以要人为规定截止日期,尽可能速战速决),两个组积累的数据量差异可能会非常大,理论上来说,数据样本积累的越多,得出的结果越接近真实情况,反之数据越少结果的偶然性就越大,但拿两种不同量级的数据进行对比是非常不合理的;对此补救的办法是,曝光先达到4000的广告组暂停,没到4000的组继续开着直到两组广告曝光量差不多,然后进行比较,但这又会引起另一个变量:时间的变化,唉,真是按下葫芦起了瓢;
3. 位置:
SB广告后面又新增了搜索结果底部以及产品详情页的展示位,这些位置由于可见性不同导致点击率也会有差异,而且SB广告的数据呈现还没有像现在的SP广告这样将不同位置的数据分开,这就导致得到的数据是由不同位置汇聚而来的一锅大杂烩,你拿Top位置广告的点击率和Bottom位置的广告去比较,自然也是不合理的;
实验总结:
时间和数据量的因素我们还可以通过拉长实验时间,增加实验数据量的方式来尽可能避免极端情况,但是展示位置不同是一个硬伤,SB广告测主图的方式也因此被我淘汰。
广告测主图方案2——SP广告Top位测主图
方案2存在的问题和方案一差不多,只不过由于数据展示位置比较清晰,少了展示位置这一干扰因素,实验步骤为:
选择一个流量比较大的关键词
用精准匹配
设置较低竞价,确保三个位置都不会有展示
大幅提高Top位置溢价比例,确保广告只展示在Top位置
先用第一张图投放,积累充足的数据后换第二张图
保证换图前后的广告的曝光都大于4000后,对比数据
实验步骤:
先确保FBA到货,然后创建2个新的FBM链接
新创的链接,主图分别用需要测试的图片,标题、价格等因素要保持一致
新链接详情页的5点、产品描述等要做出区别,防止系统认为是重复链接而被Merge
分别创建广告,具体方法同方案2
对比两组广告数据,测试过程中如果FBM链接有出单,用FBA库存给客户发货
测试结束后关闭测试链接
新创的链接由于是不同ASIN,属于竞争关系,不会出现一个广告展示而另一个广告不展示的情况,避开了广告算法问题
解决了由于广告投放时间不同带来的误差
解决了由于广告展示位置不同带来的误差

解决了之前用广告测主图,通过对比换主图前后的数据产生的投放时间不一致的问题;
亚马逊对Listing关键词的抓取,对ASIN的收录等等,都是按照原始版本来的,我们的实验组不会对亚马逊的SEO产生任何影响,所以你就放心大胆的测吧。
ASIN 资格:如果 ASIN 属于您的品牌,且最近几周内获得了足够多的浏览量,方符合试验要求。我们只允许您对高浏览量 ASIN 进行试验,以增加您在试验结束时胜出的可能性。根据分类,高浏览量 ASIN 每周可能收到几十个或更多的订单。
您对商品描述所做的更改幅度太小,无法显著改变买家行为
浏览量不够高,不足以确定置信水平较高的获胜商品描述
您测试的两个版本的商品描述在推动销量方面拥有相似的效果
大多数买家在做出购买决定时并不关心您对商品描述做的更改
有时候实验无法得出哪个版本更好,但这个“无结果”本身都是很就是一个很有价值的结果,因为它可能说明了以下问题:
两个版本差异还没有明显到影响客户行为的问题,所以用哪个版本都行;
数据量太小,不足以得出准确的结论,所以广告烧起来吧;
两个版本的改动之处都在宣传相同的卖点,只不过是换着花样说,有可能都(不)能打动客户;
改动的这个点其实是客户不关心的卖点,就是我们常说的自嗨点,白白浪费一个卖点的展示位,换个其他卖点再来试试。





目录
坑产该如何计算呢?
影响曝光的是关键词排名,如果其他因素指标没问题的话,好的产品会进入“关键词排名提高——曝光增大——坑产GMV增加——关键词排名进一步提高”的良性循环,直到你前面挡着一个比你各方面指标更优的产品;
我们常说的转化率越高,自然排名越高,这个逻辑是没问题的,但转化率只是关键词排名众多影响因素的其中一个因素;
点击率很重要,它会直接影响有多少流量进入你的详情页面,否则转化率再高,产品也会陷入到无米下锅的尴尬境地;
客单价的影响也不容小觑,某些类目下高低客单产品共存时,高客单在推排名方面会有些优势,有时卖一个产品等于低客单卖10个,虽说高客单价的转化也会低一些,只要不是标品类目,转化率总不至于比别人低10倍吧。同样的,如果两个产品每日出单相同,其中高客单的产品由于能带来更多的GMV,其在BSR排名和关键词排名下都会更靠前一些。
Tips:假设两个产品的坑产GMV完全相同,但是客单价一个高一个低,亚马逊会让谁的排名在前面呢?
转化率高的产品排名更靠前,因为转化率高说明满足了更多人的需求,照顾到了更多人的购物体验,这样更符合亚马逊以客户为中心的价值观。由于此时坑产GMV相同,高客单价产品一定是转化低的,所以高转化的低客单产品排名会更靠前。例如下图:
主图
标题
价格
Review
FBA
折扣力度
Deals标志
配送时间
BS或AC标
选择两张要进行对比测试的产品主图分别放在两个新开SB广告中,
选择一个流量比较大的关键词
用精准匹配
保持竞价相同
投放相同的一段时间
保证两组广告的曝光都大于4000
两组广告必须都是新开的,防止因为其中一组广告存在历史积累权重影响实验结果;
选择大流量词是为了尽快积累足够多数据,防止测试花费太长时间;
选精准匹配是为了确保流量来源一致的,因为不同的关键词往往代表的是不同需求,对产品图片的好恶也会存在差异;
竞价相同倒不是因为担心广告展示的位置不同,(记得那时头条广告还只展示在搜索结果头部位置)单纯是为了确保两组广告初始条件一致;
投放时间段一致是为了确保排除掉极端情况的出现(例如旺季和淡季广告的效果也会有差异性)
曝光大于4000是我人为设置的一个节点,防止数据样本过少,导致结果出现偶然性,虽然数据越多结果肯定越准确,但还要考虑测试的成本,综合下来,我认为4000的曝光量已足以完成实验;
实验缺陷:
2. 数据量:
即使我们设置了相同的竞价,相同的预算,但有时就是会出现一个广告组数据贼多,另一个却一直跑不出什么数据的情况,到了实验规定的截至日期之后(由于实验会产生时间和金钱成本,所以要人为规定截止日期,尽可能速战速决),两个组积累的数据量差异可能会非常大,理论上来说,数据样本积累的越多,得出的结果越接近真实情况,反之数据越少结果的偶然性就越大,但拿两种不同量级的数据进行对比是非常不合理的;对此补救的办法是,曝光先达到4000的广告组暂停,没到4000的组继续开着直到两组广告曝光量差不多,然后进行比较,但这又会引起另一个变量:时间的变化,唉,真是按下葫芦起了瓢;
3. 位置:
SB广告后面又新增了搜索结果底部以及产品详情页的展示位,这些位置由于可见性不同导致点击率也会有差异,而且SB广告的数据呈现还没有像现在的SP广告这样将不同位置的数据分开,这就导致得到的数据是由不同位置汇聚而来的一锅大杂烩,你拿Top位置广告的点击率和Bottom位置的广告去比较,自然也是不合理的;
实验总结:
时间和数据量的因素我们还可以通过拉长实验时间,增加实验数据量的方式来尽可能避免极端情况,但是展示位置不同是一个硬伤,SB广告测主图的方式也因此被我淘汰。
广告测主图方案2——SP广告Top位测主图
方案2存在的问题和方案一差不多,只不过由于数据展示位置比较清晰,少了展示位置这一干扰因素,实验步骤为:
选择一个流量比较大的关键词
用精准匹配
设置较低竞价,确保三个位置都不会有展示
大幅提高Top位置溢价比例,确保广告只展示在Top位置
先用第一张图投放,积累充足的数据后换第二张图
保证换图前后的广告的曝光都大于4000后,对比数据
实验步骤:
先确保FBA到货,然后创建2个新的FBM链接
新创的链接,主图分别用需要测试的图片,标题、价格等因素要保持一致
新链接详情页的5点、产品描述等要做出区别,防止系统认为是重复链接而被Merge
分别创建广告,具体方法同方案2
对比两组广告数据,测试过程中如果FBM链接有出单,用FBA库存给客户发货
测试结束后关闭测试链接
新创的链接由于是不同ASIN,属于竞争关系,不会出现一个广告展示而另一个广告不展示的情况,避开了广告算法问题
解决了由于广告投放时间不同带来的误差
解决了由于广告展示位置不同带来的误差
解决了之前用广告测主图,通过对比换主图前后的数据产生的投放时间不一致的问题;
亚马逊对Listing关键词的抓取,对ASIN的收录等等,都是按照原始版本来的,我们的实验组不会对亚马逊的SEO产生任何影响,所以你就放心大胆的测吧。
ASIN 资格:如果 ASIN 属于您的品牌,且最近几周内获得了足够多的浏览量,方符合试验要求。我们只允许您对高浏览量 ASIN 进行试验,以增加您在试验结束时胜出的可能性。根据分类,高浏览量 ASIN 每周可能收到几十个或更多的订单。
您对商品描述所做的更改幅度太小,无法显著改变买家行为
浏览量不够高,不足以确定置信水平较高的获胜商品描述
您测试的两个版本的商品描述在推动销量方面拥有相似的效果
大多数买家在做出购买决定时并不关心您对商品描述做的更改
有时候实验无法得出哪个版本更好,但这个“无结果”本身都是很就是一个很有价值的结果,因为它可能说明了以下问题:
两个版本差异还没有明显到影响客户行为的问题,所以用哪个版本都行;
数据量太小,不足以得出准确的结论,所以广告烧起来吧;
两个版本的改动之处都在宣传相同的卖点,只不过是换着花样说,有可能都(不)能打动客户;
改动的这个点其实是客户不关心的卖点,就是我们常说的自嗨点,白白浪费一个卖点的展示位,换个其他卖点再来试试。


 热门活动
热门活动 
 福建
福建 01-08 周四
01-08 周四
 热门报告
热门报告 










