




AI 背后的印度数据标注生意


像 Infolks、iMerit 和 Playment 这样的数据标注外包公司,正将印度打造成全球人工智能公司的“数据后台”。
编者按:原文作者 Anand Murali, 原文标题 How India's data labellers are powering the global AI race
Kumaramputhur 是在喀拉拉邦帕拉克卡德西北方向约45公里的一座小村庄,大约有3500户人家,可能比班加罗尔郊区大不了多少。这里没什么值得称道的产业。男女比例和文化水平都处于全国平均水平以下。除了能够看到一些现代社会的痕迹以外,Kumaramputhur 似乎没有什么特殊的地方。
高中辍学的 Mujeeb Kolasseri 就在这个村里带领一支200多人的团队,为美国、欧洲、澳洲和亚洲的人工智能公司服务。Infolks 公司于三年前创办,而28岁的 Kolasseri 是这家公司里年龄最大的员工。
在帕拉克卡德通往科泽科德的高速公路旁,有一栋不起眼的办公楼,里面大部分的团队成员都在忙着标注自动驾驶车上车载摄像头所拍摄的照片,他们要在其中标记出车辆、交通信号灯、路标和行人的影像。
除了摄像头拍摄的照片,还有一些影像来自被称作激光雷达(LIDAR)的远程传感器,这些远程传感器能创建3D地图,以帮助自动驾驶车辆感知其周围的物体。这些数据要比摄像头的影像数据更难精确标注。

Infolks 公司位于喀拉拉邦 Kumaramputhur 的办公楼 | 图片来源:FactoryDaily
在大约2000公里开外,靠近加尔各答西南边 Metiabruz 地区胡格利河岸边,约有200位女员工正在标注图像,用来训练自动驾驶汽车和增强现实系统的算法。
在印度和美国运营的数据注解公司 iMerit 的技术和营销部副总裁 Jai Natarajan 表示:“这些员工所做的是我们最尖端的图像项目。”也就是说,这些员工标注和准备的,是用于训练人工智能算法的数据。
在 iMerit 位于加尔各答、兰契、布巴内斯瓦尔、威扎吉和西隆的办事处内,还有数千名员工也在从事类似的工作,他们在标注数以百万计的数据点,这些数据会被世界各地的公司用来训练人工智能算法。
如今全球的巨头企业纷纷发展人工智能,越来越多用来训练人工智能的数据集被打上了“企业专有权”的标签,这就要求企业和数据标注团队在需求、质量控制、反馈和成果交付方面的互动更加紧密。
经历了世纪之交业务流程外包(business process outsourcing)的热潮之后,印度人对这些企业的需求和所用术语并不陌生。和业务流程外包类似,数据注解和数据标注重在对工作流程的管理,以达到精准作业,而其所需技能即使是高中学历的人也可以通过训练掌握。

在 Metiabruz 中心的 iMerit 创始人兼首席执行官 Radha Basu | 图片来源:FactorDaily
这类工作最开始以众包形式(编者注:即个人或私人团体直接从网上领取任务)为主,但随着更高级的需求出现,出现了像 Infolks、iMerit 和 Playment 这样的公司。这些公司服务于来自全球的客户,逐步将印度打造成了一个新兴的数据标注和数据注解工作中心。
印度软件与服务业企业协会(Nasscom)高级副总裁兼首席战略官 Sangeeta Gupta 表示:“在印度,这算是一个新兴的行业……大家渐渐意识到这一行业即将开启的巨大机遇。人工智能需要借助于被正确注解、分类和进行匿名处理的数据。在这件事上,无论人们观念如何,除了自动化手段以外,娴熟的工人同样必不可少,这便是印度的机遇。”
根据研究公司 Cognilytica 的一份报告显示,人工智能和机器学习相关的数据准备方案的市场规模在2018年为5亿美元,这一数字预计在2023年年底达到12亿美元。
什么是数据标注?
数据标注和数据注解,即对数据集通过贴标签、做记号、标颜色或划重点的方式,来标注出其中目标数据的不同点、相似点或类别。这些数据集可以是非结构化的,比如来自摄像头、传感器、电子邮件和社交媒体等,也可以是结构化的,比如来自数据库。经过这样的处理,用来训练人工智能的算法便可以正确地识别数据并进行学习。
打个比方,假如你想要用车载摄像头拍摄的图像训练一种算法,让其读懂路标,数据注解员或标注员就会利用注解工具仔细审查一遍图像数据集,标记或圈出不同的路标,并将这些标记好的数据提供给人工智能算法进行学习。当下次该算法在实际行驶中遇到某个区域内的路标时,便能加以识别。一个算法经过越多数据的训练,它的精确度就越高。

Infolks 创始人兼首席执行官 Mujeeb Kolasseri | 图片来源:FactorDaily
从互联网、社交媒体、传感器和其他来源获取的大量数据推动了人工智能或机器学习的迅猛发展。现今的算法能处理更多数据,于是其准确度也就更高。只要数据始终优质、便于识别,向算法输入百万个数据集,便能逐步提高其准确性。也就是说,AI 行业会一直需要更多准确注解和标注的数据。
根据 Cognilytica 的一份报告显示,目前,在大多数人工智能和机器学习项目中,数据准备和数据工程占了八成以上的时间。
总部位于班加罗尔和旧金山的 Playment 公司高管 Siddharth Mall 讲道:“就拿自动驾驶汽车来说,一小时的视频数据可能需要800个工时来处理。”该公司主要服务于自动驾驶汽车行业。
Infolks 的发展历程
Kolasseri 高中辍学后便进入铝加工行业,但之后由于健康问题不得不离开这个行业。他家里,他在亚马逊的众包平台 Mechanical Turk (MTurk) 上注册 ,开始承接来自全球各地公司的数据注解工作。
Kolasseri 说道:“在 MTurk 上,我保持着99.8的高评分,因为我交付的质量很高。有一个公司很认可我的工作,便直接联系我,给我了很多活。” Kolasseri 紧接着便组建了一个六人团队来完成这一工作。“最初,我们都在家里干活,到2016年年初,我们的业务更多了,于是便决定注册成立公司。”
创业之初,Kolasseri 的兄弟和朋友投资了25000印度卢比(约合362.39美元),帮助建立了这家公司,后来他们成为了董事会成员。如今,Infolks 成为一支不断壮大的团队,其大部分员工都来自 Kumaramputhur 及其周边地区。
Kolasseri 坦言:“公司的愿望是将我们的小村庄变得国际化,并为农村地区的年轻人提供更多谋生的机会。我们近200名员工中,90%都是20到25岁。”

在位于 Kumaramputhur 地区的 Infolks 办公室内,Kolasseri 与他的团队成员们正在交流互动 | 图片来源:FactorDaily
Infolks 的团队为多个领域提供数据服务,譬如医疗、机器人和农业等,他们约75%的工作涉及自动驾驶汽车领域。Kolasseri 的客户们包括德国汽车公司戴姆勒以及其他一些跨国高科技公司。 Kolasseri 表示,由于签署了保密协议的关系,他并不方便透露这些公司的名字。
在进行注解作业时,Infoks 一般会使用客户提供的工具,若客户没有提供的话,会借助第三方工具。Kolasseri 说道:“我们的研发团队正在开发我们自己的注解工具。目前正在测试阶段,应该在未来几周内就会推出。”Infolks 还在科泽科德地区附近的一家科技园设立了另一处办公室。他希望这一举措能提升公司营业额,因为新办公室位于一个经济特区或者说税收飞地,这有助于扩大其全球客户群。
印度人工智能的“后台”
亚马逊 MTurk 曾是印度热度很高的数据标注和注解众包平台,很多印度人在上面寻找这一类工作,但后来 MTurk 开始限制非美国工人。尽管 MTurk 后来取消了这些限制,但随着企业客户开始更加重视数据安全性,MTurk 在数据标注员中的热捧度开始下滑。此外,包括 Spare5、Cloudfactory 和 Figure 8 在内的新众包平台也进入了这一市场,这些平台更加专注于数据注解和标注。
Kolasseri 表示:“在创办公司之前的2015年至2016年间,我一直在 MTurk 平台接任务,但现在有更多类似的众包平台。但由于企业客户愈发关注数据安全,尤其是他们对大量数据集拥有专有产权,他们也就越来越不放心把这一类工作交给平台上的工人。”

图标来源:FactoryDaily
Playment 公司由 Flipkart 前员工 Mall、Ajinkya Malasane 和 Akshay Kumar Lal 共同创立,这家公司进入数据注解和数据标注行业的方式略有不同。
他们为各种应用场景开发了大量的注解工具并自己开发了一个众包平台。这个平台上的员工全部接受过培训,能使用他们所开发的注解工具。Playment 直接与有数据注解或标注业务需求的客户或 IT 服务公司合作。
Mall 解释道:“要将原始的数据转换为有注解的结构化数据,客户需要前端注解工具和熟练且划算的工人。另外,由于需要处理的数据量很大,客户还需要合适的中间平台来支持不同的工作流程,以及远程管理工人。”
据 Mall 称,Playment 的众包平台拥有超过30万名的数据注解员和数据标注员,其中获得公司认可的“高技术的一流工人”约有2.5万名,这些人几乎全天候都在平台上保持在线,平均月收入在20000印度卢比(约合290美元)至30000印度卢比(约合440美元)之间。
Playment 的大部分业务来自国际客户,包括三星、滴滴出行、阿里巴巴、Drive.ai 和德国大陆集团,这些业务大多涉及自自动驾驶汽车领域。
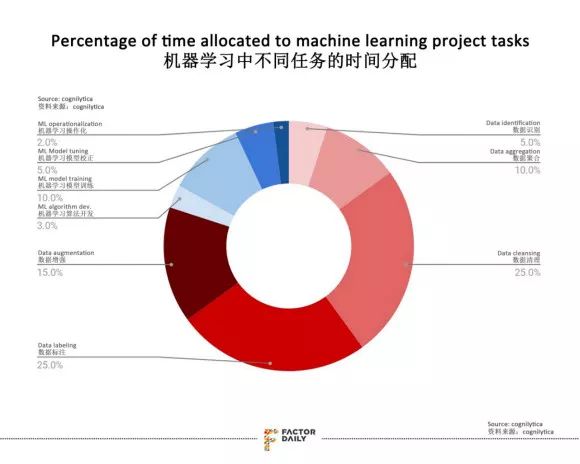
图表来源:FactorDaily
iMerit 的发展战略以员工为中心。公司2000多名员工中大约80%来自月收入低于100美元的家庭,其中大约一半为女性。Natarajan 表示:“我们的社会使命是在贫困社区中、以及缺乏公司和产业的地区创造技术就业的机会。我们在科技相对落后、科技就业机会较少的城市开展业务。”
这种所谓的利他主义有其商业上的道理。Natarajan 补充道:“工作的地区和员工决定了我们能低成本高收益地扩大注解和标注团队的规模,同时交付高质量的工作。”
尽管 iMerit 大部分的业务来自美国——其客户包括微软、易趣和猫途鹰,但其大约90%的数据注解和标注工作都在印度完成。
自动化数据注解
许多公司都在着手开发数据注解专用的自动化工具,但由于许多数据都需要按细致微妙的、客户指定的方式来注解或标注,自动化工具要能准确完成这样的任务还需要一段时间。
Natarajan 表示,不同于5年前用于区分猫狗的人工智能技术,如今的人工智能需要处理更高级的工作。他说:“机器学习已经向前发展了,已经很久没有人要数据标记员来区分猫和狗了。如今,每家公司都有着定制化并非常细化的要求,因此难以对其实现自动化,公司也不可能想都不想就把数据丢给一群匿名的(网络工人)进行标注。”

Jai Natarajan,iMerit 技术和营销副总裁 | 图片来源:FactorDaily
Natarajan 认为,基于人工智能的自动化注解工具必然诞生,但这并不会是一个威胁。Natarajan 表示:“自动注解工具本身,也需要用经过注解的高质量的数据集来训练。在你试图解决一个问题时,这些工具只能将你带到某个高度,而要超越这一高度的话,必然需要定制化的注解。”
但最终,自动化工具会变得更有效率,足以创建高质量的数据集。“长期来看,我们的工作就是不断淘汰我们所使用过的技能。当我们帮助客户达成需求,我们标注这一类数据的技能也就没用了,因为经过训练的人工智能已具备了结构化相关数据的能力。”Natarajan 说到:“但我们也发现这并不绝对,因为(人工智能)始终是一个不断学习和优化的过程。另外,客户们会继续研发新算法、解决下一个问题,而我们的工作又会重新开始。”
换句话说,印度的数据标注和注解公司尚未触顶。
编辑:奥利





")






















