





半年12.8亿美金,以为没什么机会的赛道,疯狂融资

在今天回顾过去一年 AI 应用层的进展,AI 搜索一定是难以忽视的一个方向。在很长的一段时间里,AI 搜索=Perplexity,在榜单上,几乎感受不到其他搜索产品的存在。但市场,似乎在释放新的信号。

一方面,信息检索是能与当前大模型能力匹配的一大应用场景;另一方面,AI 搜索明星产品 Perplexity 流量仍在稳步增长,体现出用户端对搜索体验升级的新需求。即使 AI 搜索也存在种种问题,例如 PMF 的验证、尚难以难以撼动传统搜索引擎等等,且依旧被创业者视作“LLM 初期最有可能跑出 Killer APP 的领域”,很被资本看好。
Perplexity 最新估值 30 亿美金,基本属于估值第一梯队的纯 AI 应用(不做模型)公司。它仅在今年上半年就完成了两次融资,两轮融资总额超过 7000 万美元。但是大家聚焦 Perplexity 这一“资本宠儿”的上半年,资本还默默投出去了 12.1 亿美金。
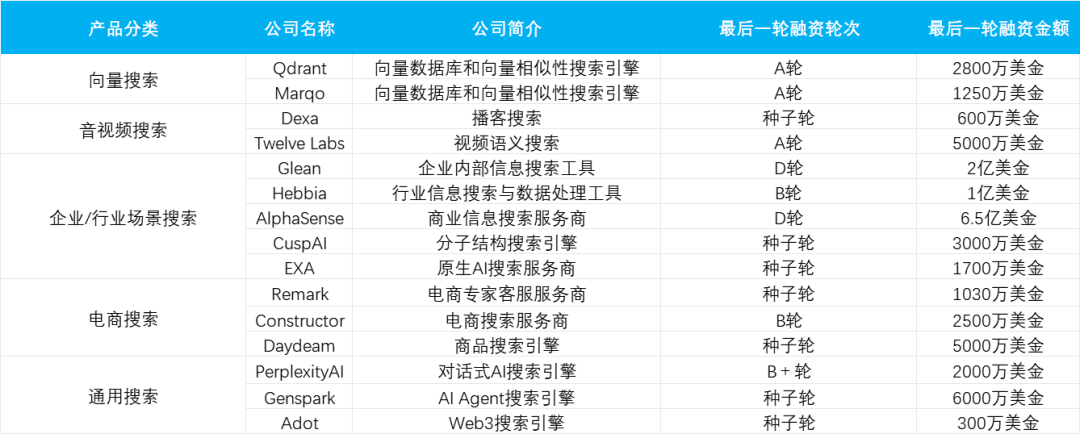
上半年15起 AI搜索融资,不同应用场景项目占比
上半年,我们根据公开信息统计了共计 15 起 AI 搜索领域的投融资,我们发现:
1、面向企业\行业场景的 AI 搜索企业获投最多,前者也是最容易获得单笔大额融资的 AI 搜索落地场景;
2、另一热门落地场景是电商+AI 搜索,在获投项目中,其与通用搜索的占比均为 20%;
3、播客搜索等相对“小众”的场景下也出现了融资案例。
这些资本青睐的 AI 搜索产品到底都长啥样?
Dexa ——搜索播客知识点,向“专家”提问


如果你经常听播客,大概率都曾遇到过一个问题,某天心血来潮想起之前在播客中听到的一个精彩洞见,想要回听,却怎么都记不起它是来自哪一位主播,哪一个单集。即使幸运地锁定单集,又在时间戳的帮助下将范围缩小到 20 分钟的片段,也只能选择自行听完或者转录成文字后查找,非常费时。Dexa 的创始人 Riley Tomasek 也曾有过类似困扰,一次耗时的查找之后,他决定打造一款面向播客场景的 AI 搜索工具。
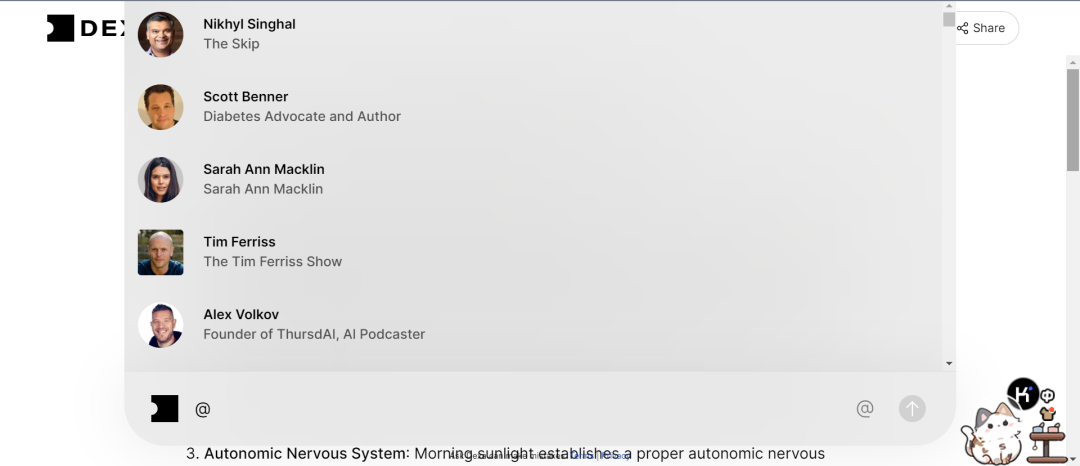
Dexa 没有详细阐释过产品的技术路线,但表示自己使用了先进的索引技术,将基于主播、单集和节目三个维度的知识图谱提供准确和高效的搜索服务,它的核心数据源来自 120 多档播客节目,并且仍在持续地添加中,包括知名的《Tim Ferriss Show》《Huberman Lab》等等。产品设计中,Dexa 的一大核心理念是“向专家提问”(如图所示),搜索时用户可以选择向特定的主播提问(或者不限定主播),健康、商业、科技、个人成长等领域的问题都是大热门。
搜索结果以 AI 总结的形式呈现,并附上对应播客谈及该问题的具体时间戳,点击即可收听。搜索结果也支持用户一键分享,一部分内容有机会直接出现在 Google 的搜索结果中,从而带来网站的自然流量。但 Similarweb 数据显示,今年 6 月 Dexa 的网站月访问量大概在 29 万次左右,相较今年 2 月 100 万月访问的水平大幅度下滑。
白鲸评论:产品好、场景小众。查找听过的播客实在不是一个太高频的应用场景,Dexa 目前的数据库体量也限制了它向其他应用场景拓展。截至今年 2 月,Dexa 尚未开始产生收入,TechCrunch 就播客 AI 搜索的创业方向与一些播客转录、数据库产品的创业团队交流过,他们表示 AI 搜索的成本问题是一大考量因素。
Twelve Labs——生成视频难,不如先“理解”视频


Twelve Labs 是一家致力于打造多模态“视频理解”(Video Understanding)基础设施,以实现对视频进行语义搜索的 AI 公司。
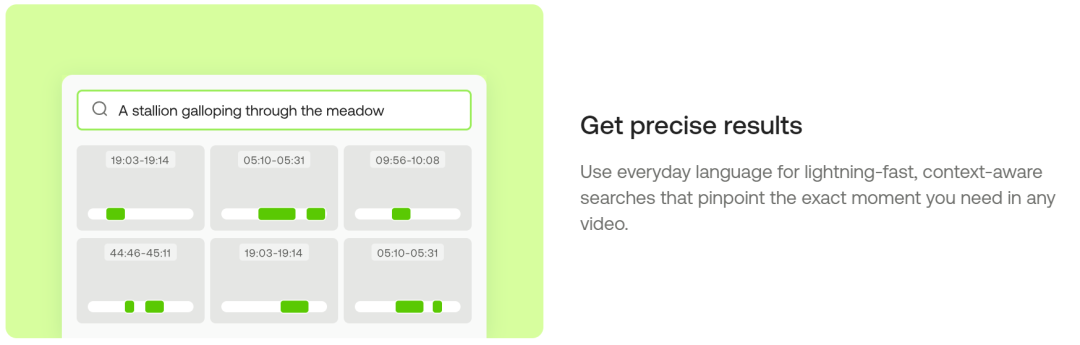
技术特点:根据官网介绍,借助于旗下的 Marengo 模型,Twelve Labs 可以实现快速对大量视频内容进行索引(即转换成可以被快速检索和访问的形式),让用户能够通过自然语言来搜索和访问存储在视频中的各种信息。
Twelve Labs 认为视频最为接近人们体验的“现实”,而大语言模型在视频领域的能力有限。而其打造的多模态大模型 Marengo-2.6 最快能在 15 分钟内索引 1 个小时的视频,并实现文本到视频、文本到音频以及图片到视频的搜索任务。
应用场景:目前 Twelve Labs 已与媒体和娱乐、广告、自动化及安全等多领域的客户展开合作,例如借助 AI 视频搜索实现快速标记赛事精彩瞬间、查找监控录像等。
在 AI 视频搜索之外,Twelve Labs 最新大模型 Pegasus 能够实现视频到文本的转换,目前正在 Beta 测试中。Pegasus 能够进一步理解复杂视频,具备总结、查询、回答及分析能力。据悉 Twelve Labs 在训练基础模型时,会同时训练模型的多个部分,使得模型的整体大小只有原来的 1\5,也提高了计算效率和能源效率。
DayDream——强大的创始团队,能搞定一个新入口需要的流量吗?
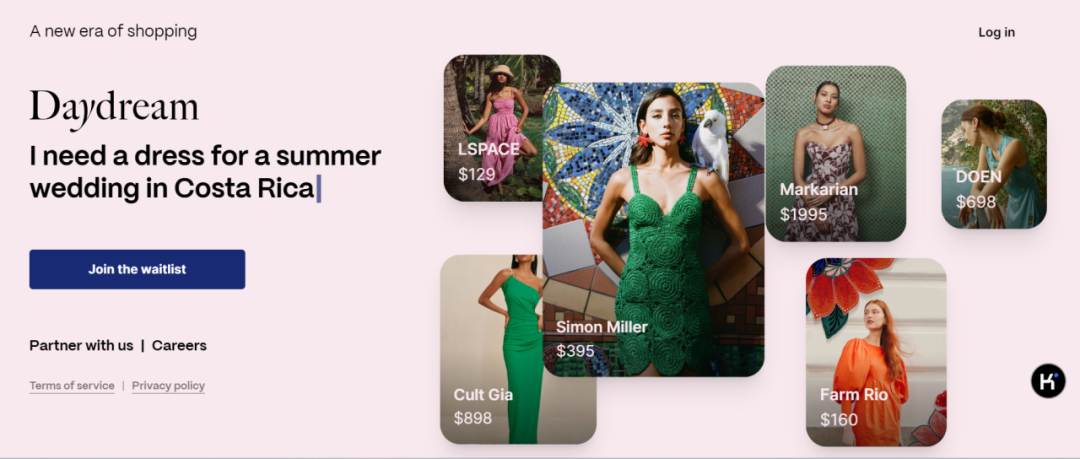


购物或许是快乐的,但是购买决策常让一些消费者感觉“筋疲力尽”,为解决上述问题,一批电商场景的 AI 搜索产品应运而生,DayDream 就是其中之一。
它支持用户使用自然语言或者图像识别进行搜索,使用时,用户只用说明使用场景就能找到心仪产品。比如提问“这个夏天我要去海边参加婚礼,请给我一些着装建议”;再比如,用户可以上传一张蓝色裙子的照片,并提问,“我很喜欢这条裙子的款式,但是我想要一条红色的。”改进的重点在于使得整个交互体验更加个性化,推荐更具针对性。
为实现上诉搜索体验,DayDream 选择将现成大模型微调,并创建了一个包含众多产品类目的数据集。它计划于今年秋天在美国开启 Beta 测试,上线之初 DayDream 将专注在时尚领域,合作对象包括 Net-A-Porter, Altuzarra, Jimmy Choo, Doen, Alo Yoga and La DoubleJ.在内的 2000 余个时尚品牌。
白鲸评论:今年上半年,电商领域的 AI 搜索融资不少,但是像 DayDream 直接打造 ToC 产品却不多,主要是因为竞争相当激烈。像亚马逊、Google 以及 TikTok 等巨头都在自研用 AI 优化购物体验,体量小一点的电商平台也在尝试接入外部解决方案来集成 AI 搜索(下文还会提及)。这一波趋势里,一个全新的商品发现入口需要的流量成本估计高得惊人。目前看起来,DayDream 受资本认可的一大原因是团队背景很强。
DayDream 的创始人 Bornstein 此前创立的 AI 购物初创公司 The Yes 被 Pinterest 成功收购,其 CPO 和 CTO 分别来自 Google 的人工智能研究小组和微软的数据和应用科学团队,CCO 和 CSO 也分别曾在 Google 的时尚商务拓展部门和 Pinterest 的购物策略团队任职。从技术到市场,都有人在。
Constructor——“十年老兵”的思考,AI搜索落点在转化
应用场景:Constructor 是一家成立近 10 年的电商服务商,专注于为电商客户提供产品发现相关的配套服务,涵盖从搜索到浏览、推荐、收藏、商家智能(数据分析)、用户测试、AI 购物助手(ASA)在内的各个方面。其最新推出的 ASA 解决方案与 DayDream 提供相似功能,即当购物网站选择集成后,用户可以通过自然语言交互的方式获得个性化的商品推荐,而商家通过消费体验的改善提升客户满意度和销售额。
技术特点:ASA 的原理是通过用户的点击行为数据、Transformers 模型和大语言模型来快速识别用户的搜索意图。而除了优化搜索体验之外,Constructor 也会向商家提供配套的数据分析功能来提升转化率。截至今年上半年,Constructor 已为超过 1000 亿次客户互动提供支持,该公司的客户量在过去一年中增加了 50%,并且在过去三年中保持了 98.5% 的平均客户留存率,丝芙兰、Target 在内的知名电商平台都是其客户。
Remark——真人工·智能
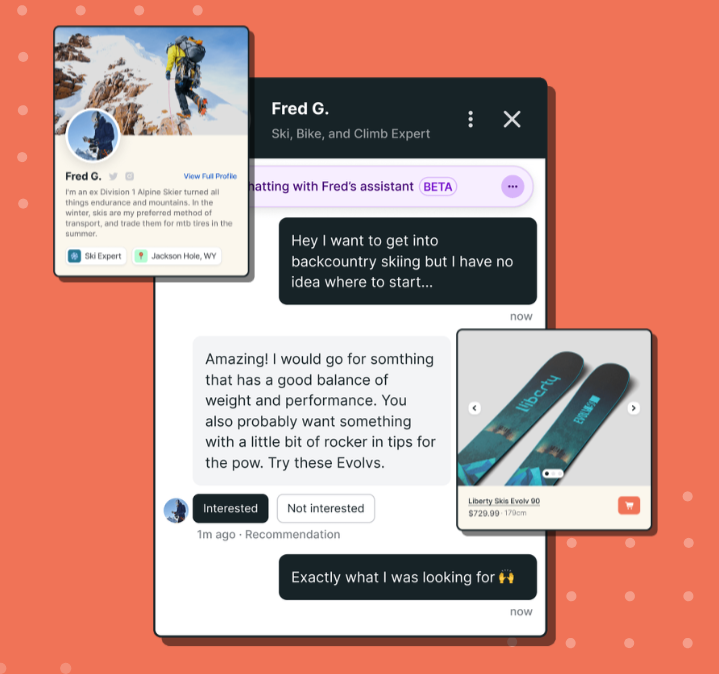
同样是帮助用户进行购物决策,如果说 DayDream、Constructor 专注于搜索环节的优化,Remark 则尝试建立另外一种匹配机制,它引入真人专家,想给予用户 VIP 般的购物体验。
技术特点与数据来源:Remark 引入的真人专家包括艺术家、音乐家、造型师、高尔夫球手以及滑雪教练等,它将服务集成在品牌的独立站中,用户可以随时向真人专家寻求购物建议。而如今 Remark 开始用 50000 名专家的数据训练 AI,当专家离线时,AI 也能提供服务,并且成交后会抽取一部分佣金给到专家。
应用场景:一个典型的应用场景是,当进入一个滑雪户外产品独立站时,新手用户可能会对区分滑雪板的型号、尺寸和适用场景等无从下手,它通过 Remark 的专家匹配服务获得极具针对性和专业的购买建议。Remark 目前主要与户外用品、婴儿用品、美容护肤品等行业的客户合作,其公布的数据显示集成相关服务后客户的收入增长了 9%,转化率提高了 30%。
白鲸评论:相较于用 AI 取代人工客服的“大趋势”,Remark 积极引入专家导购可谓是出了一个奇招,并且即使加入了 AI 也是异常克制地、仅起到辅助专家的作用。印象颇为深刻的是,Remark 团队其实非常强调消费者在购物中的情感体验,而他们认为正是人的加入让这一体验得以完整,这也是过去在线电商所忽视的部分。某种程度上,你可以认为 Remark 打造的购物决策流程是希望兼顾理性和感性的,足够理想化,但其涉及到相当高的沟通成本,或许只会在高客单价、有认知门槛的品类中有生存空间。
Adot——web3 与 AI 搜索


技术特点:Adot 是一款采取去中心化架构的搜索引擎,不依赖中心服务器,把数据存储在多个节点中。此外,Adot 还引入了激励机制,使用搜索引擎或者参与数据收集、索引、分析、整理的用户,都可以获得虚拟货币奖励。
应用场景:Adot 是一个通用搜索引擎,但大多数用户会通过 Adot 获取对于加密货币市场的洞察和与 Web3 相关的知识和新闻。
数据来源:Adot 融合了 Web2 和 Web3 的数据,除了传统网页外,它还包含区块链数据、社交媒体数据、Web3 交易数据等。
Genspark——“小红书版”AI搜索引擎

2023 年,Bing 在全球搜索引擎中的市占率虽然不到 4%,但是其全年收入却达到了 120 亿美元。换句话说,AI 搜索即使仅从传统搜索引擎中抢到1%的市场份额,也是相当大的一块蛋糕。这句话是 Perplexity 创始人对自己的“安慰”,也同样适用于 Genspark。
Genspark 将自己定位为一个 AI Agent 引擎,面对各类问题,有专门 AI Agent 进行执行研究并产出名为 Sparkpages 的自定义页面。这一页面的输出原则是,摒弃所有的偏见和 SEO 驱动的内容,综合可信信息,提供有价值的结果和节省用户时间。具体来说,Genspark 目前主攻旅行、商品两大垂类方向的内容搜索业务,Sparkpages 作为 AI Agent 生成的优质网页承接最终搜索结果。
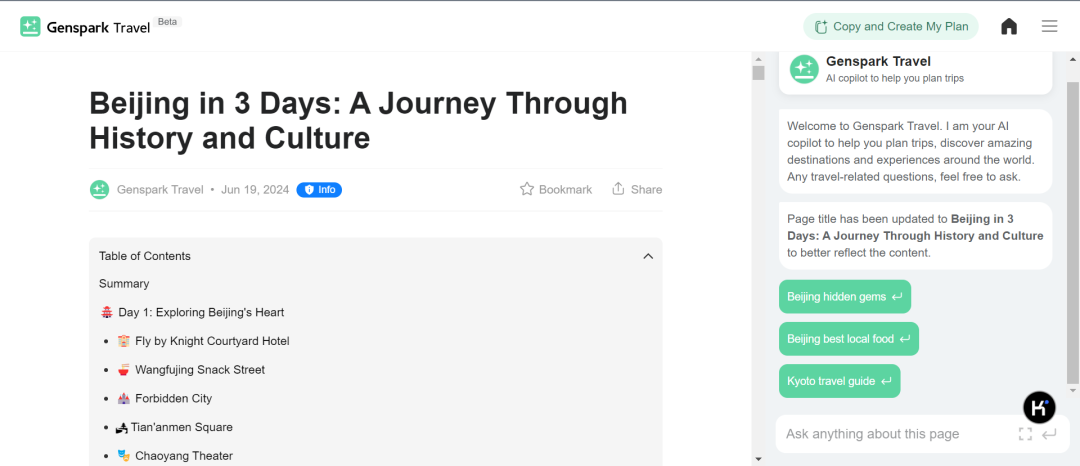
例如当用户输入“北京三日游出行建议”的问询,将跳转自 Sparkpages 页面,它将以类似小红书图文信息流的形式呈现多个结果,用户可以点击感兴趣的结果查看详细信息和进行进一步问询,这种图文结合的内容组织形式其实也比较匹配 Genspark 目前切入的旅行和商品的品类,体现差异化的同时也能够迅速占领用户心智。
Qdrant

技术特点:Qdrant 是一个开源向量数据库和和向量相似性搜索引擎,用 Rust 语言编写。互联网上的文字、图片、音视频等模态的数据都可以转换为向量,并在向量数据库存储,这种存储方式的好处是,可以用更少的空间存储数量更庞大的数据,并可以更方便地对数据进行快速检索和高效管理。
而向量相似性搜索引擎中的向量,可以看作传统搜索引擎中的关键词和网站链接。通过向量搜索引擎,用户可以快速找到数据库中与输入向量相似的向量,然后再将向量转换为相应的文字、图像、音视频等信息来使用。
应用场景:向量数据库及搜索引擎是一个重要的基础设施,主要通过 API 和客户端库供开发者使用,它广泛地应用于个性化推荐、文本/图像的处理与识别、实时数据分析与监测等领域,用来快速查找向量数据库中相似的向量,并转换为常规数据进行使用或分析。
数据来源:向量数据库中的数据来自公开数据集、网络爬虫、第三方数据服务商等渠道的文字、图片、视频、音频等模态的向量数据。
Marqo
技术特点:Marqo 提供的功能与 Qdrant 类似,但 Marqo 使用更大众化的 Python 语言编写,可以无缝集成 Python 机器学习项目和数据库,更适合中小开发者使用,在Python开发者社区中也非常受欢迎。但是 Marqo 在处理高并发需求、大规模数据等复杂业务场景的性能不如Qdrant。
应用场景:Marqo 更适合 Python 项目或中小开发者相对简单的项目,而 Qdrant 更适合需要处理大量数据和高并发请求的大企业使用。
数据来源:与 Qdrant 相同。
Glean ——估值已经 22 亿美金的打工人搜索引擎
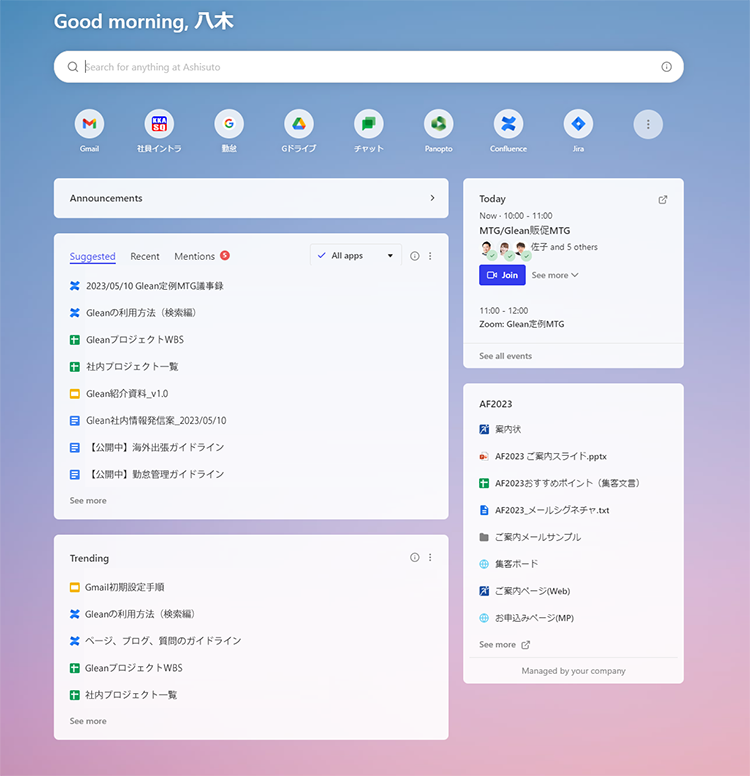
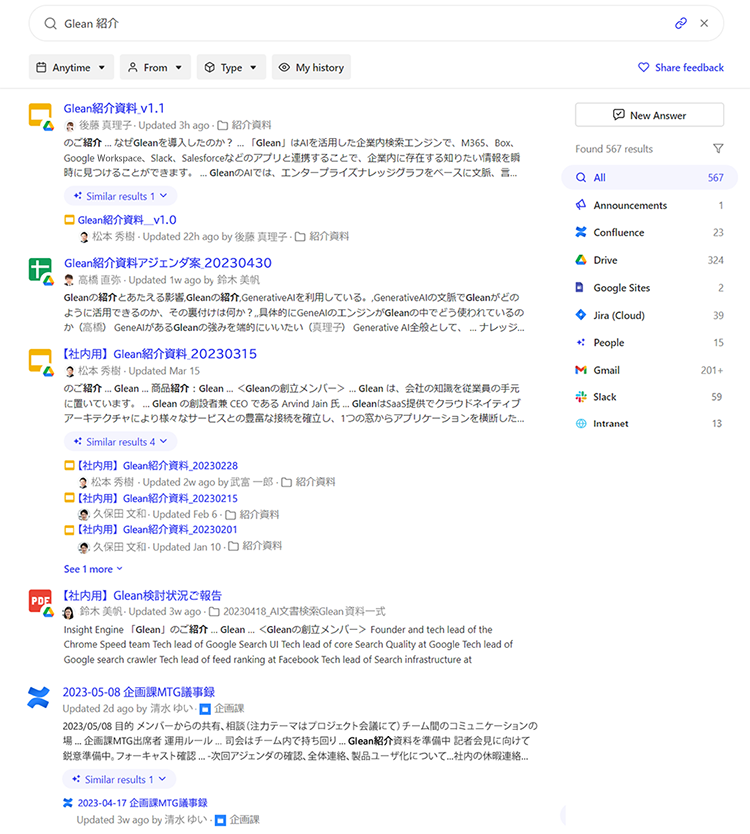
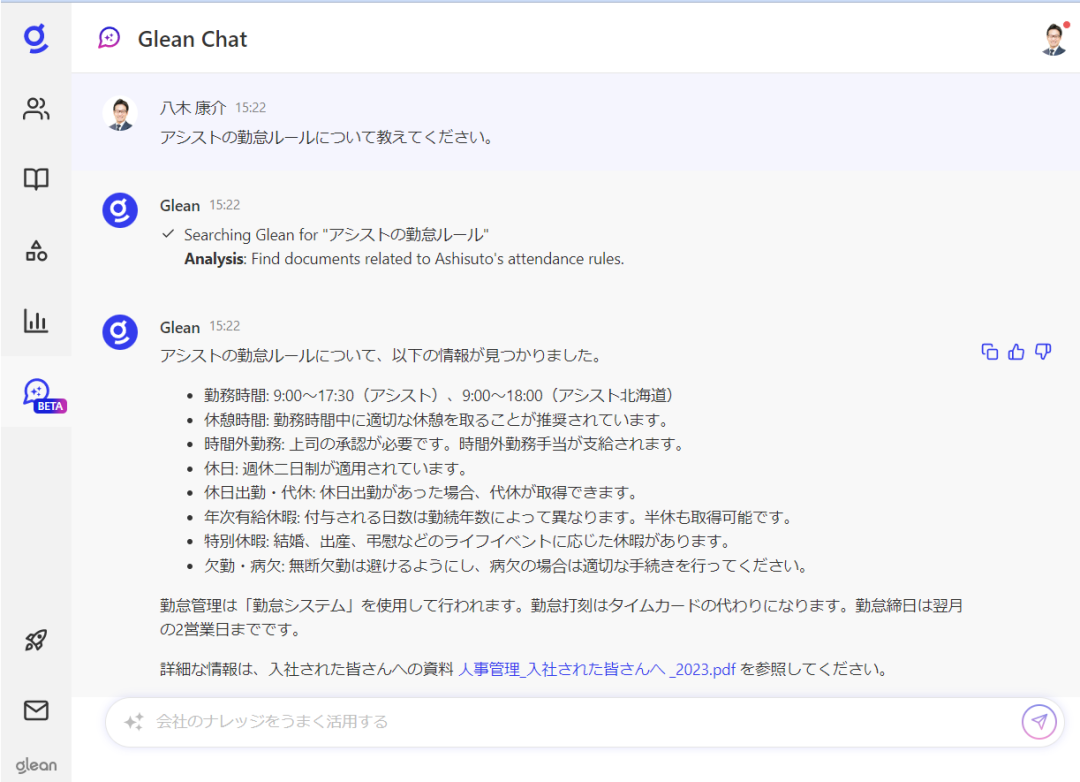
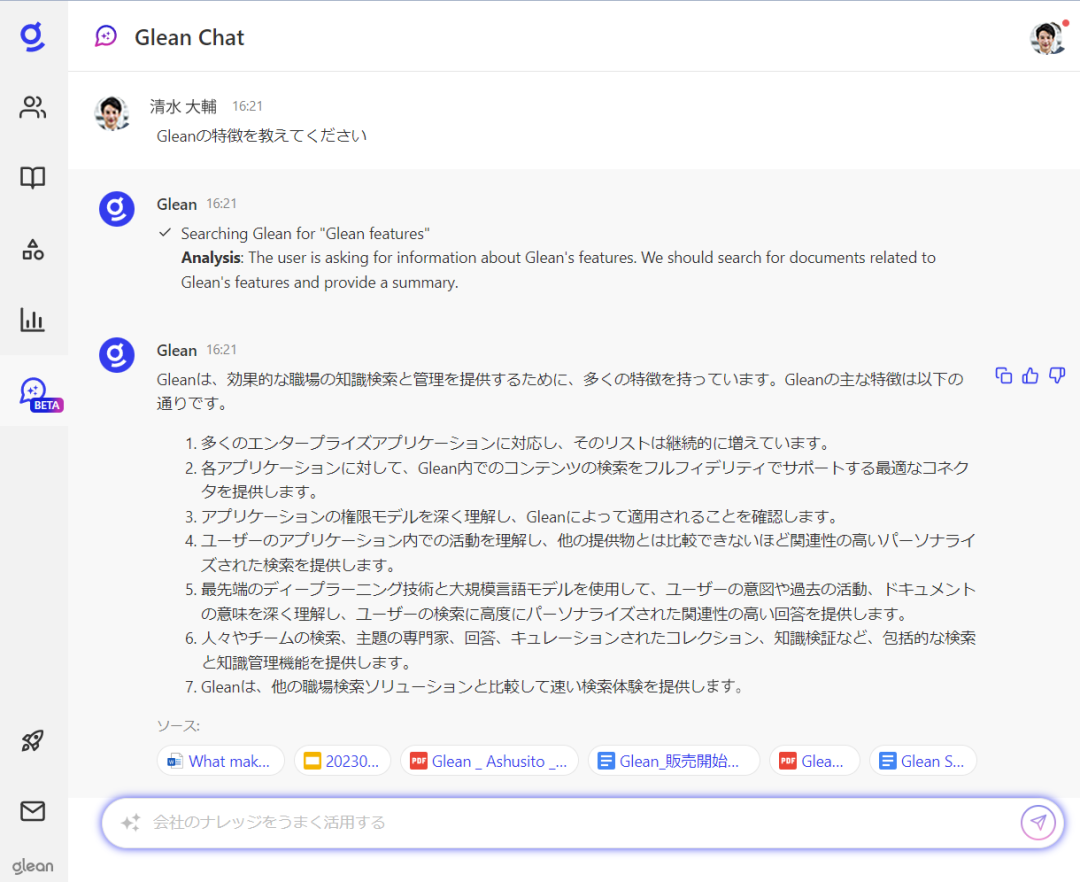
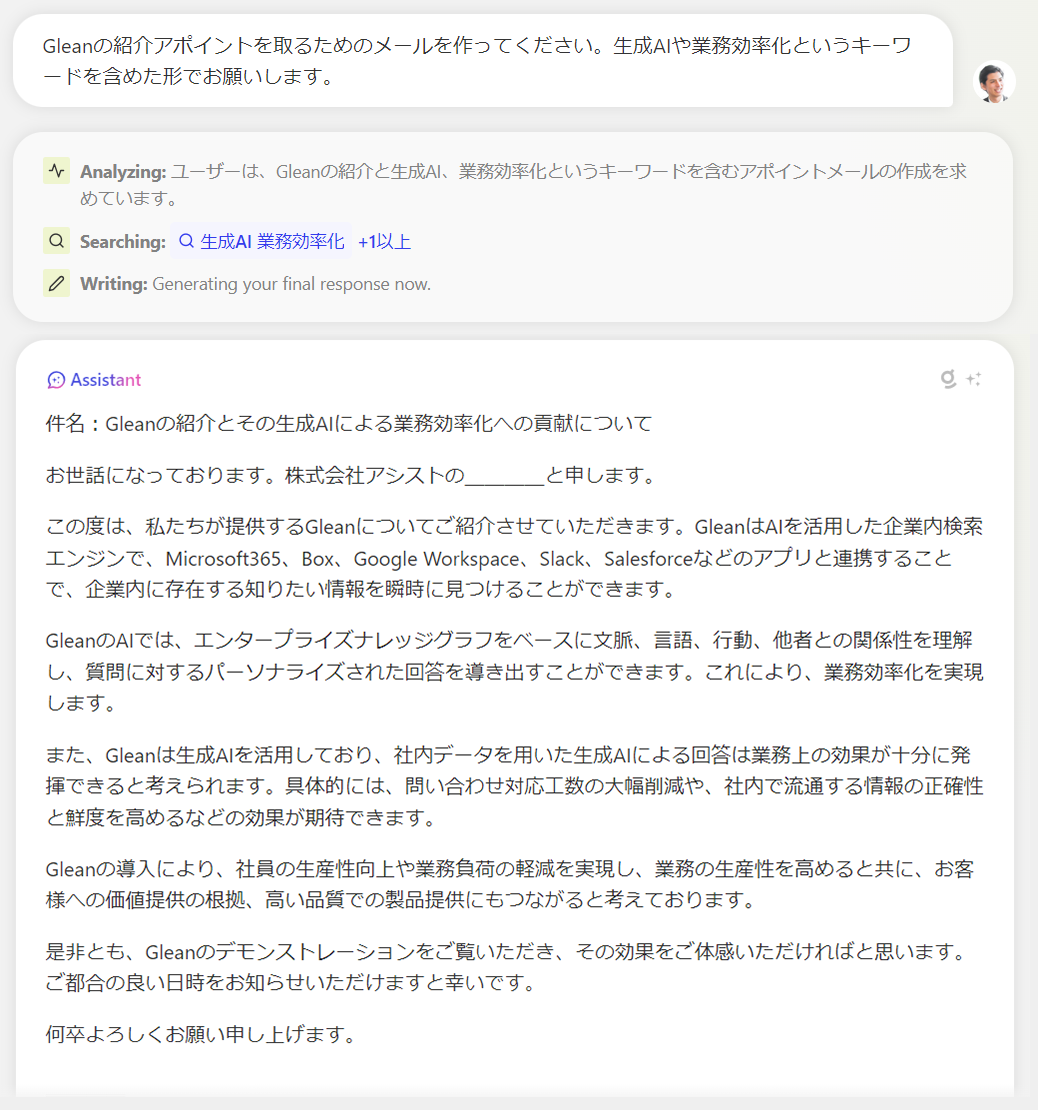
技术特点:Glean 是一款以搜索为核心的工作助手。它可以在公司内部各数据源中(包括 Outlook、Office、Google Workspace、Salesforce 等)进行交叉搜索,给出用户需要的文件、数据,或直接就问题给出答案。AI 会针对搜索者的职位和搜索习惯优化呈现的结果,即使搜索相同的关键词,同公司不同岗位的员工,也会获得不同的结果。
除了传统模式的搜索引擎之外,用户还可以在 AI Chat 功能中直接询问 AI 或者用自然语言进行搜索,AI 在给出答案的同时,还会给出该内容出自哪个文档。此外,用户还可以在所有的文档中看到与这个文档有关的同事(比如作者、审批者等),方便公司进行信息的管理和协作。
除了搜索功能外,Glean 还提供 AI 生成文字内容、管理日程安排、预定会议、快速访问常用文档和应用等便捷功能。据媒体报道,Glean 使用了包括 GPT 在内的多款大语言模型。
应用场景:Glean 并没有特别针对的行业,算是一款工作场景通用的效率工具。
数据来源:互联网公开信息、企业内部数据。
Hebbia—— 金融行业起步,ARR 已过千万美金
总部所在地:美国纽约
视频来源:a16z
技术特点:Hebbia 的核心产品名为 Matrix,是一款主打专业化数据处理的 AI 工具。它可以从多个形式不同的文件中检索和提取多种数据,交叉核对后,在文档或表格中输出用户需要的数据。用户可以自定义任务内容,也可以将本次任务保存为模板,以便在日后的工作中使用。同时,在 AI 执行任务的过程中,用户可以监控 AI 每一步检索和校对的过程,了解这些数据的出处。
用户还可以基于 Matrix 接入的所有数据源,询问 AI 相关问题,比如,让 AI 直接给出所有目标公司中年增长率超过 5 倍的公司名单。
应用场景:Hebbia 目前专注于金融行业,它使用的 AI 模型也针对金融行业进行了特别训练,用于市场研究、证劵、投资、审计等多个细分场景。目前 Hebbia 的 ARR(年度经常性收入)已经达到了 1300 万美金,其 7 亿美金的估值约为 ARR 的 54 倍。
在拿到融资后,Hebbia 开始把应用场景扩展到法律、咨询、政府、军工、制造业、制药等多个行业中。
数据来源:公开信息、企业内部数据库、第三方数据库。
Alphasense——已经快上市的金融行业专用搜索引擎
总部所在地:美国纽约
创始人:Jack Kokko
创立时间:2023 年
最后一轮融资:2024 年 6 月 11 日完成 6.5 亿美金 D 轮融资,Viking Global Investors 和 BDT & MSD Partners 共同牵头,Google 参与,融资后估值为 40 亿美金。

技术特点:AlphaSense 又是一款专为企业和金融专业人士设计的搜索引擎,它整合了网络上关于金融市场的公开信息和一些内部信息,用户可以通过关键词搜索或与 AI 对话来搜寻信息。AI 在给出信息和行业观点后还会提供根据,以便用户进行交叉验证。
AlphaSense 自行研发了适应金融领域的大模型 AlphaSense Large Language Model,这款模型可以理解复杂的金融术语和市场动态,基于大模型能力,AlphaSense 可以从大量文件中提取相关信息,进行分析,并输出行业观点。
根据高盛的数据, AlphaSense 的 ARR 高达 2 亿美金,目前正在准备上市。
应用场景:AlphaSense 的主要用户群体有金融分析师、企业战略决策者、市场研究人员等,用来快速搜索市场数据,辅助他们做出分析与决策。
数据来源:公司文件、公开的财务数据、市场研究报告、专家分析、新闻报道、企业内部报告等。
CuspAI——材料专用 Search Engine

技术特点:CuspAI 是一个材料学“搜索引擎”,用户输入用户理想中材料所需具备的特点与属性,AI 就会依据掌握的知识快速筛选不同的分子结构,给出一个或是几个可行的材料分子结构,供研究人员进一步研究。
应用场景:CuspAI 主要应用于各种科研场景。最近,团队正在用 CuspAI 设计一种可供捕获和存储碳的材料,它可以吸收空气中的二氧化碳,并存储下来。
数据来源:专业数据库。
EXA——“针对”SEO,准确的链接优先于关键词
技术特点:EXA 是一款适应人工智能时代的搜索引擎,可以在复杂搜索场景下,满足 Google 和 Bing 无法满足的搜索需求。
与 Google 最大的不同是,EXA 的 AI 模型使用了 Transformer 架构,搜索引擎可以直接理解用户的语义,并直接给出与语义最相关的链接,而不是靠关键词进行搜索,再让 AI 基于关键词搜索的结果进行整合。
这样的模式能使获得的结果更加精准,也能够排除 SEO 的影响,尤其适合复杂场景下的搜索。
应用场景:EXA 的使用场景主要是面向 B 端的,虽然 C 端用户也可以在网站端使用,但绝大多数用户是通过 API 调用,使用 EXA 的服务的。
比如 AI 写作助手可以调用 EXA 的 API 直接查找与用户具有相似想法的论文或者 Blog,并将答案整合进输出中,提高内容的质量。EXA 还可以应用在企业市场调研、金融、法律等对信息质量要求较高,任务也相对复杂的搜索场景。
数据来源:互联网公开数据。
查找投融资信息时,我们也尝试查找国内 AI 搜索产品的投融资线索,结果发现,国内公司做AI的思路基本上都是将搜索功能整合进“大而全”的 AI 产品中,很难将其定义为单纯的 AI 搜索产品,比如虽然大模型公司月之暗面在 5 月 22 日进行了一笔融资,但我们很难将其归于 AI 搜索领域的投融资。
而除了很难界定的产品外,我们并没有找到做 AI 搜索且在上半年获得融资的产品。这个原因可能是,目前市场上用户数量较多的 AI 产品,比如字节的豆包 、百度的文新一言、昆仑万维的天工等产品都包含了 AI 搜索功能,其他小公司靠做 AI 搜索似乎确实比较难拿到融资。






")






















