





通过竞品广告报告搭建词库

通过竞品广告报告搭建词库
运营中必要的插件经过了极致的数据处理,已经十分全面精准。而对于追求推品成功率的单干卖家和部分精品公司,竞品广告报告也是提高推品成功率的不二之选。
本文架构:
竞品广告报告的选择方法 竞品广告报告处理的底层逻辑 竞品广告报告的处理与实操 插件与相关网站的使用场景
一、竞品广告报告的选择
首先,为什么不用商机探测器计算转化率?因为商机探测器计算出的转化率是过去360天内,这个关键词下所有产品的平均转化率。 我做的类目不是很红海的类目,因此,多数产品,我会选择2个与自己产品在外观、功能、属性、价格区间、目标人群最相似、且在bsr上的竞品买广告报告;再选择1个与自己产品最相似,且在nr上的竞品买广告报告。如果认为nr1的水平大概不如自己,我会选择3个与自己产品最相似、且在bsr上的竞品买广告报告。 如果是红海,建议买4-5份。为什么选3-5个竞品:数据量越大,偏差越小3-5个竞品是多数人在广告报告价格接受范围内,可参考性较强的数量。下文提到的竞品广告报告,默认和自己后台下载的search term搜索词报告长得一样。
二、竞品广告报告处理的底层逻辑
很多时候,人们在思考的时候相信直觉,相信自己的经验并做出判断。但很多时候,这些经验可能是错误的。因此,我会给出直接并有说服力的论证,证明用竞品广告报告的有效性,与处理数据的有效性;而不仅仅停留在“显而易见,我认为”、“通过直觉,我觉得”、“通过以往经验,我相信”。
首先,论证为什么选择竞品的搜索词报告对自己有用、有指导意义,但头部非标的广告报告对非标的借鉴意义有限。
引入一个概率统计/机器学习的概念,叫做“泛化误差(Generalization Error)”。泛化误差测量“一个模型对先前未知数据的预测准确程度“,具体的公式为: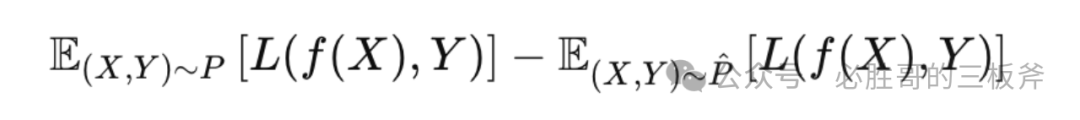 这里,P指被预测数据的真实分布,p̂指已有数据(训练数据)的分布,L是损失函数,用来衡量预测值与真实值的不一样程度,f指这个模型。
这里,P指被预测数据的真实分布,p̂指已有数据(训练数据)的分布,L是损失函数,用来衡量预测值与真实值的不一样程度,f指这个模型。
在亚马逊运营中运用泛化误差的概念,现在我们需要找到一个模型,通过已有数据,去预测我自己产品的cvr和acos。我们需要让p̂(已有数据的分布)尽量接近P(被预测数据的分布),才可以让泛化误差越小,即让预测的准确程度越高。这就是为什么我们需要挑所处阶段、流量结构、外观、功能、属性、价格区间、目标人群最相似的竞品作为数据进行我们的预测——因为最相似产品的数据(已有数据分布p̂),和我们产品的数据(被预测数据的分布P)最接近,所以可以降低泛化误差,因此可以提高预测的准确度。
论证为什么新品榜的竞品搜索词报告有充足的借鉴意义,且季节性产品的借鉴意义有限。
引入一个统计学概念,叫做“时间序列分析(time series analysis)”,意思是“将原来的销售分解为几部分来看——趋势、周期、时期和不稳定因素,然后综合这些因素,提出销售预测。”建立公式:
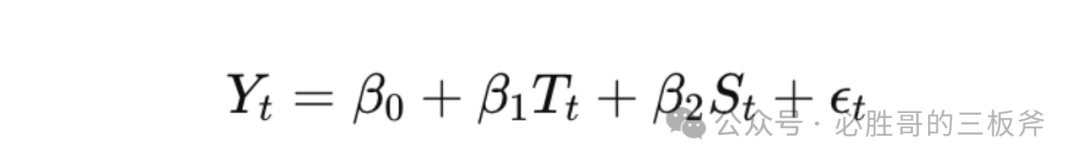
Yt指在预测的时期t的转化率,Tt为通过历史数据预测的时期t的趋势,St为通过历史数据预测的时期t的季节性/周期,ϵt为不稳定因素。
挨个分解来看。ϵt是无法干涉/预测的因素,所以只能抛开不看。由于新品的趋势Ttnew比老品的Ttold更能反映当下的趋势,整体的Ytnew会比整体的Ytold更精准,即新品搜索词报告展现的转化率,在其他条件保持不变的情况下,比老品更可以反映自己即将上架的品的转化率。
通过时间序列分析的公式,我们还可以看到影响预测值Yt的因素还有St,即季节性/周期性。当产品是非季节性产品时,这一项是0;如果是季节性产品,这一项不为0,导致预测转化率Yt的波动会非常大。因此,竞品的搜索词报告对自己即将上架的产品是否有足够借鉴意义,和该品是否具有周期性高度相关。
论证为什么bs的竞品搜索词报告有充足的借鉴意义。
引入一个统计学定理,叫做“大数定理(Law of Large Numbers)“。该定理意味着“随着样本大小的增加,样本均值将收敛于总体均值。”套到亚马逊的竞品搜索词报告上,建立公式:
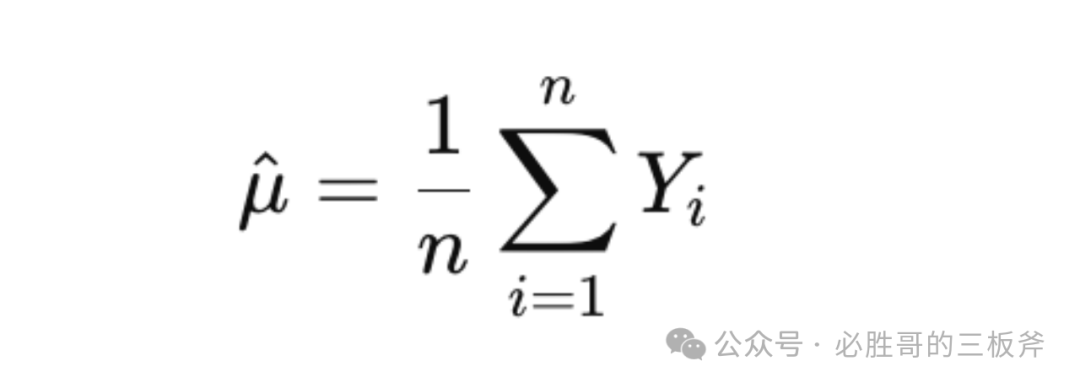
同样,拿转化率cvr举例。在这里,μ^指自己在一个搜索词下的预期转化率,Yi指每一个竞品在这个搜索词下的转化率,n是竞品/竞品搜索词报告数量。通过公式,我们可以得出,随着n(竞品搜索词报告)数量的增加,μ^可以成为真实总体转化率μ的更准确估计。但,由于新品榜的产品数量有限,所以选择去bs榜单获得更多数据,即增加n的值,从而更准确的预估自己的转化率。
不仅是cvr,acos、cpc、ctr等数值,都可以通过增加样本数量(竞品搜索词报告数量)去提高预测数值的准确度。
论证为什么取每个搜索词的平均cvr,是代表自己在这个搜索词下最有可能的cvr。
说实话,取平均值,是所有不完美的方法中最有效的一个;最有效的方法是不存在的。我们可以使用排除法去论证这个观点。但是,此方法仅适用于非季节性产品(降低趋势带来的影响),和被买搜索词报告的竞品在各个维度上与自己的产品极为相似(降低数据噪音,noise)的情况。
1)时间序列分析——ARIMA(自回归整合滑动平均模型)、Exponential Smoothing(ETS,指数平滑法)、Exponential Moving Average(EMA,指数移动平均线)
ARIMA自回归整合滑动平均模型的公式为:
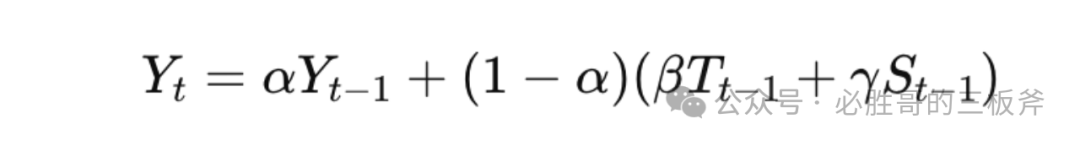
Exponential Smoothing(ETS,指数平滑法)的公式为:
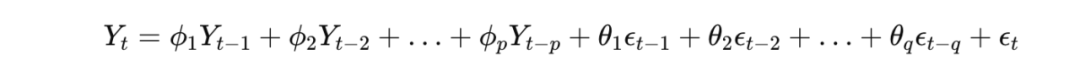
Exponential Moving Average(EMA,指数移动平均线)的公式为:
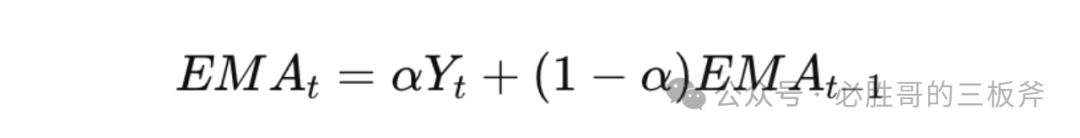
细心的读者可能会发现,两个公式都出现了一个字母:t。t意味着单个的时间点。但是,我们可以买到的搜索词报告涵盖着近两个月的整体数据,而非像第一天、第二天…或第一周、第二周…的时间点的数据,所以任何时间序列分析的模型都行不通。原因很简单,因为咱们只有一个t,即过去两个月。
2) 接下来,我们用简单移动平均线——Simple Moving Average(SMA)去证明“取每个搜索词的平均cvr,是预测自己在这个搜索词下比较可能的cvr“。
依旧拿cvr举例。假设我们买了3个竞品的搜索词报告。针对每一个客户搜索词,3个搜索词报告中单独每一天的cvr分别为Y1,t, Y2,t, Y3,t, t是1,2,…,60,代表近2个月的60天。例如,当t=3时,Y1,3是第一个竞品在第3天的cvr。
这三个竞品在过去2个月的SMA可以被计算为:

这三个竞品的整体SMA可以被计算为:
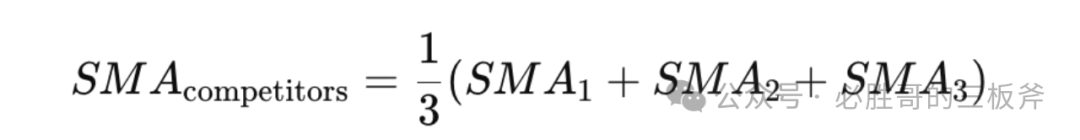
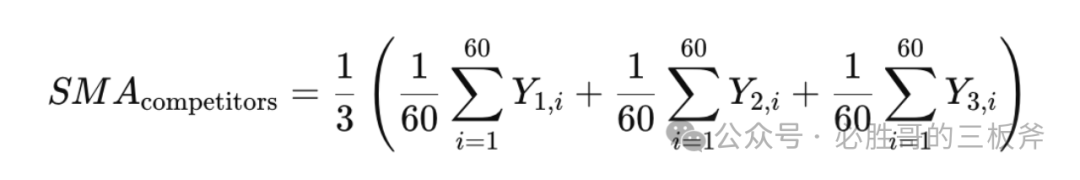
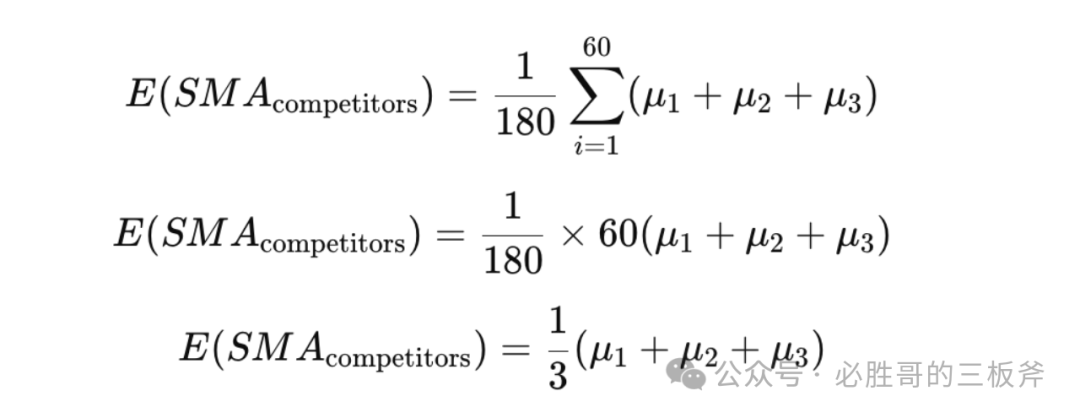
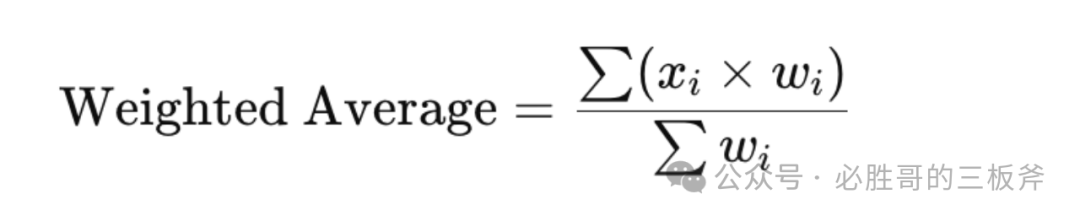
首先,运用自问自答法,列出我所需的是什么。
a.“关于词本身,我需要知道什么?”出单多的customer search term(客户搜索词,下文简称cst);提前否定哪些词;竞品打了哪些词;词根和属性词有哪些;每个词的cvr、acos及cpc;
b. “关于竞品,我需要知道什么?” 拉升时间节点;除广告外所有操作(见第三部分);
c.“我的词库还需要什么?”强中弱相关性;ABA。
d.接下来,我会讲解如何整理关键词的orders及占比、cvr、acos、cpc、词根与属性词、强中弱相关性、ABA,及需要提前否定的词根。
需要解决的问题:
a.一个cst在一份excel竞品广告报告中可能会多次出现,例如两个广泛、一个词组、一个精准、自动紧密,可能会跑出同一个cst。如何将每个cst对应的spend、clicks、orders、sales对应起来并求和?
b.求和后,如何求每个词平均的acos和cpc?
c.如何确定哪个词根需提前否定?
针对2. a) 的Excel Pivot Table解决方案:
a.可以利用Pivot Table,求和每一个cst对应的所有clicks总点击量、spend总花费、total orders总单量,及total sales总销售额。例如,有一个cst是white machine washable sheet sets,在sheet sets词组、washable sheet set广泛,white sheet sets广泛及auto紧密中都跑出来了这个词,可以自动求出四个广告组的总点击量、总花费、总单量,及总销售额。不仅如此,不像普通的SUMIF函数需要手动输入cst,Pivot Table可以自动求和每一个cst的数值总和。接下来是详细操作步骤。
b.打开竞品广告报告,在Home主页,点击Editing->Sort & Filter->Filter,使第一行每一个方框里的右侧都出现一个倒三角。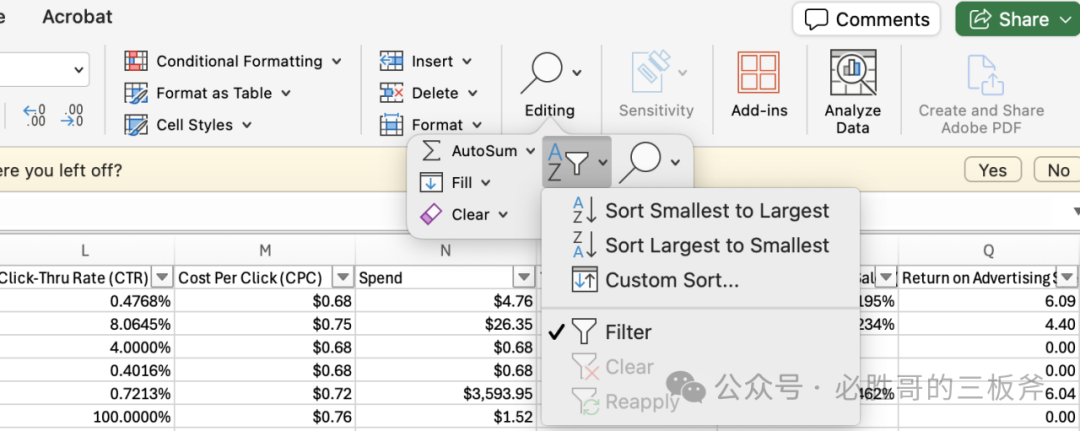 c.全选广告报告。
c.全选广告报告。
d.打开Home键右侧的Insert面板,选择最左侧的PivotTable。 e.新建的excel sheet左侧会出现一个长方形的方块,右侧会出现包括Filters、Columns、Rows和Values等方块的面板,如下图所示。
e.新建的excel sheet左侧会出现一个长方形的方块,右侧会出现包括Filters、Columns、Rows和Values等方块的面板,如下图所示。 f.点击右侧面板里上方的Customer Search Term,这时Customer Search Term会出现在Rows的方块中;而后,点击右侧面板里上方的7 Day Total Orders (#), 7 Day Total Sales ($), Spend, 和Clicks。这时,面板的四个方块应该是如下所示的。
f.点击右侧面板里上方的Customer Search Term,这时Customer Search Term会出现在Rows的方块中;而后,点击右侧面板里上方的7 Day Total Orders (#), 7 Day Total Sales ($), Spend, 和Clicks。这时,面板的四个方块应该是如下所示的。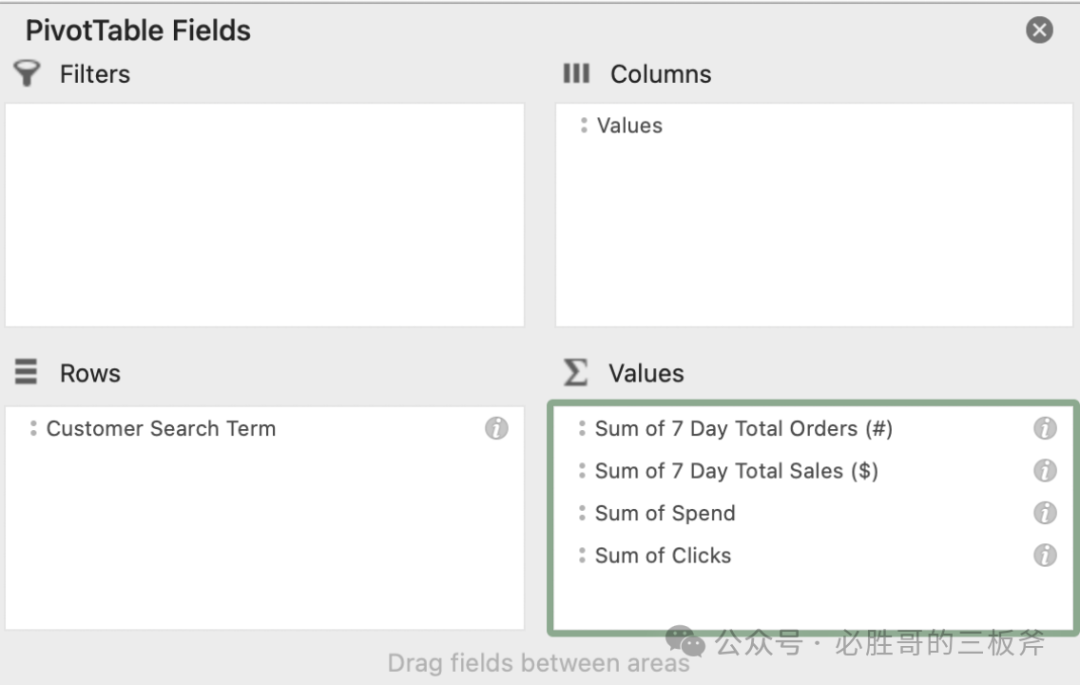 g.这个excel表格,就解决了上文第2点第a条的问题。大家可以看到现在的excel表格自动求和了每一个cst对应的所有clicks总点击量、spend总花费、total orders总单量,及total sales总销售额。
g.这个excel表格,就解决了上文第2点第a条的问题。大家可以看到现在的excel表格自动求和了每一个cst对应的所有clicks总点击量、spend总花费、total orders总单量,及total sales总销售额。
h.然后,cpc可以用sum of spend列/sum of clicks列得出,acos可以用sum of spend列/sum of sales列得出。Problem solved :)
接下来,是强中弱相关性。
打开西柚,搜索表现好的cst,放进反查关键词,判断前10自然位的产品是否和自己的产品相关。前10自然位产品中,若9个及以上和自己的产品近似,则为强相关;若5-8个近似,则为中相关;若2-7个近似,则为弱相关。
新品如何选词打?
根据相关性、流量大小(ABA)、cvr进行cst的分类。选择强相关词,表现好的中相关词也可考虑;选择高流量大词;选择高cvr词。然后,依据每个词的词根及属性词,决定打广泛、词组还是精准。
分享一个只包含词根和属性词的一部分词库,这个表格我用了正好10分钟完成关键词的整理、归类、打标签。 如何确定哪个词根需提前否定?
a.我会总结出3-5个竞品加起来出了0单的cst,放入excel表格,统计所有cst中每个词的词频。
b.和自己产品不相关的词可以尝试做否定;例如,我的产品是聚酯纤维,可以否定organic(organic在此情况中大多描述的是organic cotton材质,有机棉花)。
c.词频从上到下排序,可以得出最常见但不出单的词。可以尝试去西柚或前台搜索大词+这个词;例如,我看到3个竞品广告报告中,有一个出现频率很高但不出单的词是washable;我去前台/西柚搜washable+大词。如果相关性很弱,可以尝试做否定。
四、插件与相关网站的技巧
1.我用西柚查ABA及ABA近一年的趋势、判断关键词的强中弱相关(反查关键词->自然排名第1-第10)、广告放映机查看自己小时级的广告位(关键词分析->广告放映机)、流量得分与关键词、及广告分析部分判断竞品拉升销量的节奏。
2.我用sif的拓词功能补充自己的词库、用反查广告组功能分析很多细节(例如投放效果、投放词、匹配方式),用sif插件的运营时光机分析拉升销量及提高排名的操作手段,很好用且很精准。
3.我还用极目反查cpc及类目的特征,用来在前期判断一个市场可否进入,选品的时候极有帮助;还会查竞品的cvr并与自己的cvr做对比,判断listing或广告是否需要进一步优化、是否出了很严重的问题;搜集并总结CPR、CPA和目标排位建议,整理到词库中,辅助判断第一第二第三阶段该投放那个词。





























