





用AI来读取解亚马逊的COSMO模型

今天看到有群友在问COSMO,想看下之前法老群内,ChatGPT解读的问题是什么。在找到相关截图以后,我也想花时间让AI来协助解读下,这个上个月就见过,但是没有详细阅读的文档。
发现有了AI的出现,RPA的出现,人必须学会的是找到标准,找到自己的目标在哪,根据自己的目标制定标准,根据标准,就可以让AI以及RPA快速的去走相关的路径。
那么我们就来直接将文档放到软件看看:

COSMO是一个由Amazon.com Inc.和香港科技大学(HKUST)的Changlong Yu、Xin Liu等人共同进行的研究项目。该项目的主要研究方向是在电子商务领域中的常识推理和用户行为。COSMO团队的核心贡献者包括Changlong Yu、Xin Liu等人。他们的研究侧重于理解用户在购物过程中的常识推理和行为模式。COSMO与其他类似项目(如ConceptNet和ATOMIC)相比有着独特的特点,通过深入挖掘用户行为背后的常识推理,为电子商务领域的智能应用提供了新的思路和方法。

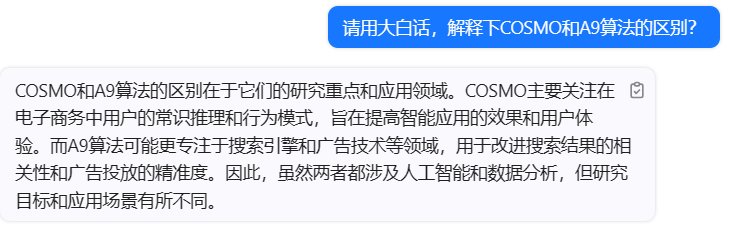

总结下:数据源越多,就可以去通过更多模型去打标签,做筛选,在数据源不够的情况下,就必须使用之前搜索和广告技术的算法。


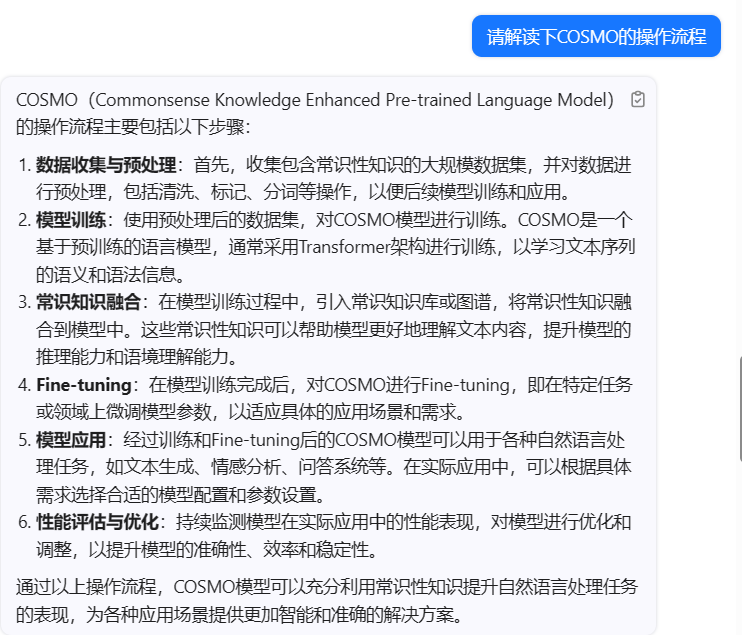
COSMO(Commonsense Knowledge Enhanced Pre-trained Language Model)的操作流程主要包括以下步骤:
数据收集与预处理:首先,收集包含常识性知识的大规模数据集,并对数据进行预处理,包括清洗、标记、分词等操作,以便后续模型训练和应用。
模型训练:使用预处理后的数据集,对COSMO模型进行训练。COSMO是一个基于预训练的语言模型,通常采用Transformer架构进行训练,以学习文本序列的语义和语法信息。
常识知识融合:在模型训练过程中,引入常识知识库或图谱,将常识性知识融合到模型中。这些常识性知识可以帮助模型更好地理解文本内容,提升模型的推理能力和语境理解能力。
Fine-tuning:在模型训练完成后,对COSMO进行Fine-tuning,即在特定任务或领域上微调模型参数,以适应具体的应用场景和需求。
模型应用:经过训练和Fine-tuning后的COSMO模型可以用于各种自然语言处理任务,如文本生成、情感分析、问答系统等。在实际应用中,可以根据具体需求选择合适的模型配置和参数设置。
性能评估与优化:持续监测模型在实际应用中的性能表现,对模型进行优化和调整,以提升模型的准确性、效率和稳定性。
通过以上操作流程,COSMO模型可以充分利用常识性知识提升自然语言处理任务的表现,为各种应用场景提供更加智能和准确的解决方案。


通过AI,加起来10分钟看完这个文档,我的感受就是,未来做任何事情,积累数据源,任何领域的数据源,构架产品知识图谱,按照不同标签进行归类,非常重要。如果没有数据源,不懂新算法下这些产品应该是如何匹配的,那么也就无法知道自己应该如何为这个系统准备数据源。
了解清楚标准以后,再对应的根据要求去准备,更容易符合要求。






























