




程博士谈大数据 | 如何利用大数据发现和拓展目标人群

营销人都希望自己的产品能卖给更多的客户,潜意识的情感里甚至希望能卖给所有的客户,遗憾的是,理智告诉我们这是不现实的。我们经常对进入中国的外资企业说“If you're selling anything other than rice, you don't have 1.4 billion customers in your reach. - 如果您卖的产品不是大米,您在中国不可能拥有14亿顾客”。

同样的,对于进入美国市场的跨境电商,您的产品也不可能被全美国1.45亿家庭的3.5亿人所喜爱和购买;在现实中,您的目标人群只可能是一部分,甚至是一小部分人。而且随着品牌和产品的多样化、消费者需求的碎片化,大部分产品的目标市场都是小众市场。所以营销人面临的挑战是:
- 如何发现我的目标人群?
- 他们有什么特点?
- 如何从现有的目标人群拓展到更大的目标人群?
 什么是目标人群?
什么是目标人群?
一个品牌每年花费数万至数百万美元的市场费用,使用散射的方法来宣传自己,然后祈祷有人会主动联系他们的公司,购买他们的产品。想象一下:一名中等收入、素食主义、全职女白领、没有主动搜索行为,某天却收到了武士刀的广告。她的反应会是什么?给没有需求的消费者滥发广告,会引起消费者反感、投诉,甚至拉黑。

为了避免浪费时间和金钱来试图吸引永远不会成为客户的人,品牌需要确定自己的目标人群。目标人群就是最有可能购买您产品的人。
 如何发现和分析目标人群?
如何发现和分析目标人群?
跨境电商在美国运营一段时间后,或多或少都会积累一定的销量。因为要配送,这些消费者要留下姓名、地址、手机、Email等信息。可是只有这些是远远不够的,我们还希望更深入的了解他们的年龄、性别、教育程度、收入、家庭人口构成、种族;家庭净资产、是否有房产、房产价值、有几辆车、什么类型的车、什么品牌的车;住在哪个城市、哪个州、哪个区域?喜欢买什么、喜欢穿什么、喜欢吃什么、社交媒体习惯等等。营销人要怎么做呢?
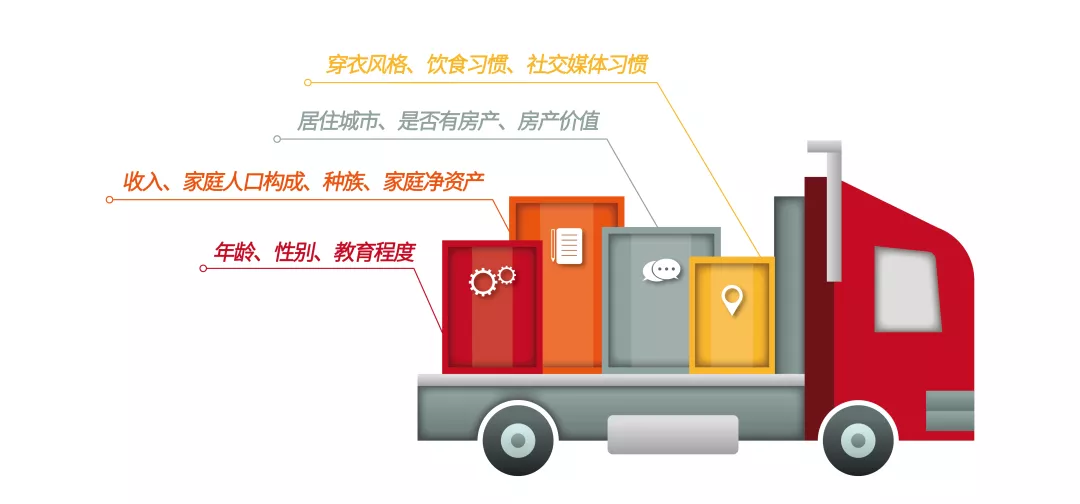
从已经购买了我们产品的消费者(种子人群)入手。假设您有1,000个种子人群,分别将这1000个种子的姓名、地址、Email与美国1.45亿家庭3.5亿人口的大数据库进行查询,如果姓名、地址等匹配成功,则将这1,000人的人文信息、财务信息、地域分布、购买行为、兴趣爱好等1500+信息附加在种子人群中,形成全景视图。这个过程叫数据增强。 对增强后的种子人群进行多维度的消费者画像,然后通过对比美国标准人群找出差异,譬如:某产品的种子人群男女比例32 : 68,而美国标准人群男女比例50 : 50;说明该产品的种子人群比较明显偏女性;按照同样的方法,分析各个维度得到该品牌的种子人群特征,示例如下: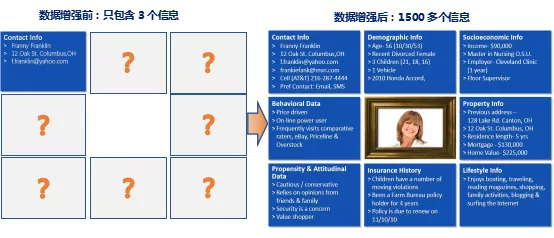

 如何拓展目标人群?
如何拓展目标人群?
利用种子人群的特征,通过一定的算法评估模型,在大数据中找到更多拥有潜在关联性的相似人群,简称相似人群扩展。常用的相似人群扩展方法有两种:
利用用户画像进行人群扩散:给种子用户打标签,利用相同标签找到目标人群。 这个方法容易理解也容易操作,但最大的问题是“非黑即白”的问题,比如:种子人群男女比例32 : 68,我们选择性别标签 “女” ,那就过滤掉了32%的男性,即使这些男性的其他特征如收入、职业、教育程度、兴趣爱好等非常符合。也就是说,它无法综合考虑所有因素,更无法知道每个因素的影响权重。 利用相似性模型进行人群扩散:种子用户为正样本,候选对象为负样本,训练这个模型,然后用模型对所有候选对象进行相似性打分。 相似性模型可以综合考虑所有影响因素,可以计算出每个因素的影响权重,不会出现“非黑即白”的困扰。假设我们最终得到的模型为:相似性=0.2*性别[女]+0.5*教育程度[本科]+0.3*收入[70,000美金以上],如果一个男性在教育程度和收入上和种子人群相似(得分高),即使性别不同(得分低),他的相似性总分仍然会很高,仍然可能是这个产品的潜在购买者。 将这个模型的公式导入大数据库,给每个人都计算出相似性得分,然后从高到低降序排列。最后这个品牌可以根据自己的预算和销售目标选择得分前5%或10%或30%的潜在购买者进行投放和推广。 模型的价值在于:它可以帮企业在同样的广告费用下,提高销售业绩;或者花更少的费用,达成同样的业绩。

备注:相似性=0.2*性别[女]+0.5*教育程度[本科]+0.3*收入[70,000美金以上],实际上的模型变量因客户行业、产品、销售方式等诸多因素大不相同;权重系数也无法提前预知,此处仅为示例。






























