









Stable Diffusion 优化亚马逊图片的思路

 2029
2029最近,AI取代运营的话题引起了广泛的关注,我也感到了一丝焦虑。然而,我认为,解决这种焦虑的最好方法就是通过持续学习,提升工作效率,以实现我们的目标。在深入研究了Stable Diffusion(SD)一段时间后,我开始思考如何将SD与跨境工作相结合。
那些对AI图片工具有所了解的朋友应该知道,这些工具的基本功能就是从文本生成图像,或者从图像生成图像。其中,Midjourney和Stable Diffusion的实用性较强。Midjourney生成的图片华丽且易于上手,但可控性较差。而Stable Diffusion虽然有一定的学习门槛,但其多种扩展功能和与ControlNet的结合可以大大增强图片的控制力。基于这些了解,我萌生了一个想法:使用SD作为优化图片的工具。
经过一段时间的学习和实践,我有了一个大致的思路:使用亚马逊的白底图进行图像生成,结合ControlNet的Canny模型定位产品的线稿,再结合prompt提示词切换背景,最后使用Photoshop等工具为图片添加文字。这个过程中,SD的使用省去了抠图的步骤,并丰富了产品的展示场景,通过AI图像生成(AIGC)提升了设计工作的效率。下面,我们来看一些具体的实例。
使用 ChatGPT 生成产品图 Prompt
文本生成图像的功能相对简单,只需直接询问GPT,引导它给出提示词即可。然后,将这些提示词输入到SD中。关于如何安装和启动SD等基础操作,在这里就不再赘述。
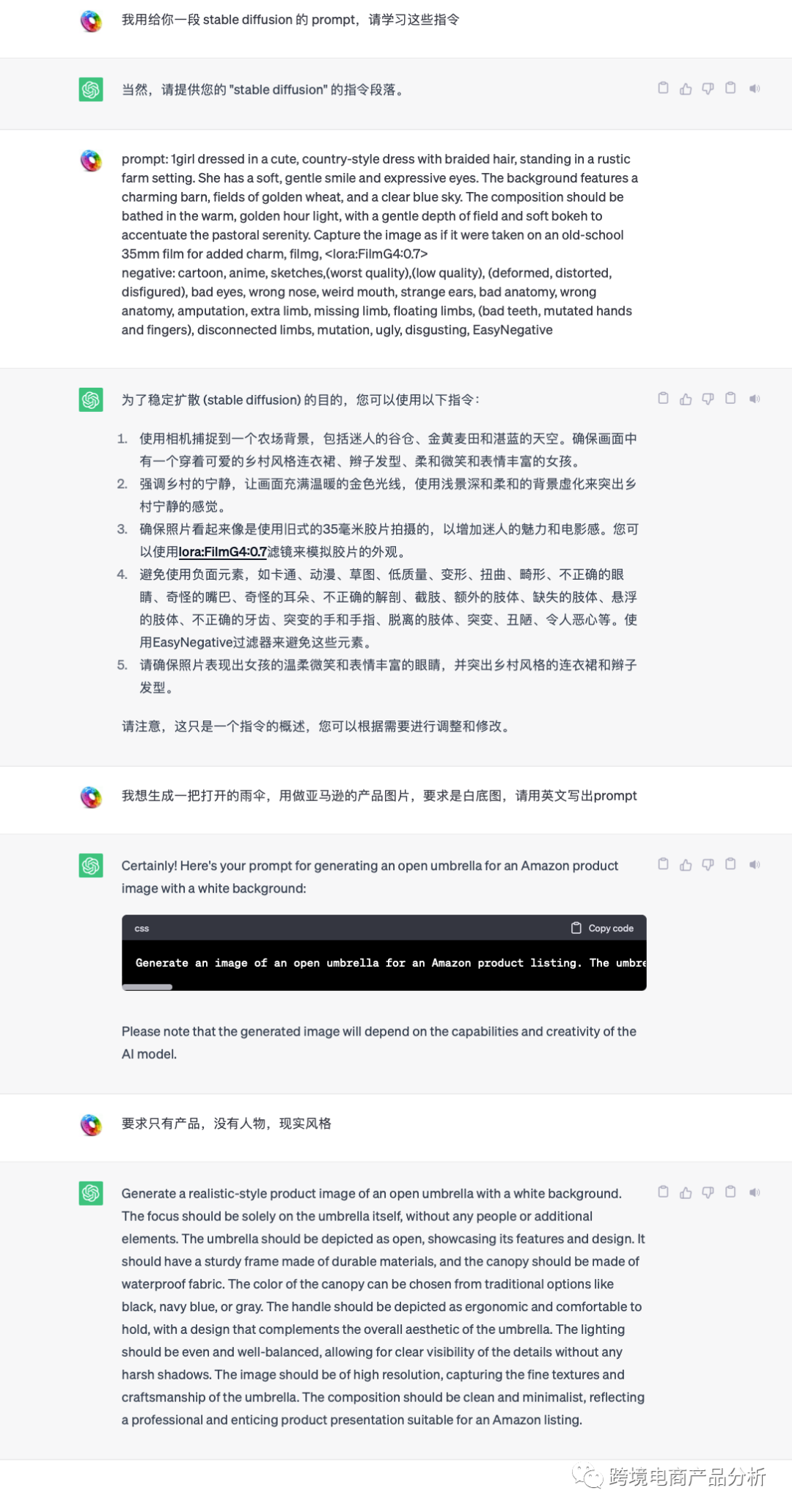 我选择了两个产品进行测试,一个是雨伞,一个是充电宝。这两个产品的区别在于,雨伞需要人物展示,而充电宝则不需要,单纯的产品展示就足够了。这样,我们可以分别测试直接的图像生成或结合ControlNet的Canny模型。
我选择了两个产品进行测试,一个是雨伞,一个是充电宝。这两个产品的区别在于,雨伞需要人物展示,而充电宝则不需要,单纯的产品展示就足够了。这样,我们可以分别测试直接的图像生成或结合ControlNet的Canny模型。
我基本上使用了默认的参数设置,只是为了测试在最基本的情况下,图片生成的效果如何。我选择的大模型是chilloutmix,采样方法是DPM++ SDE Karras,这只是出于习惯,基本上是默认设置。同时,我将每批生成的数量调整为4,以便有更多的选择。我对两个产品进行了高分辨率和非高分辨率的测试,以下是生成的结果。
由于文本生成图像的目的是进行测试,所以我并没有进行更多的调试,只选择了能完整出图展示产品进行下一步操作。
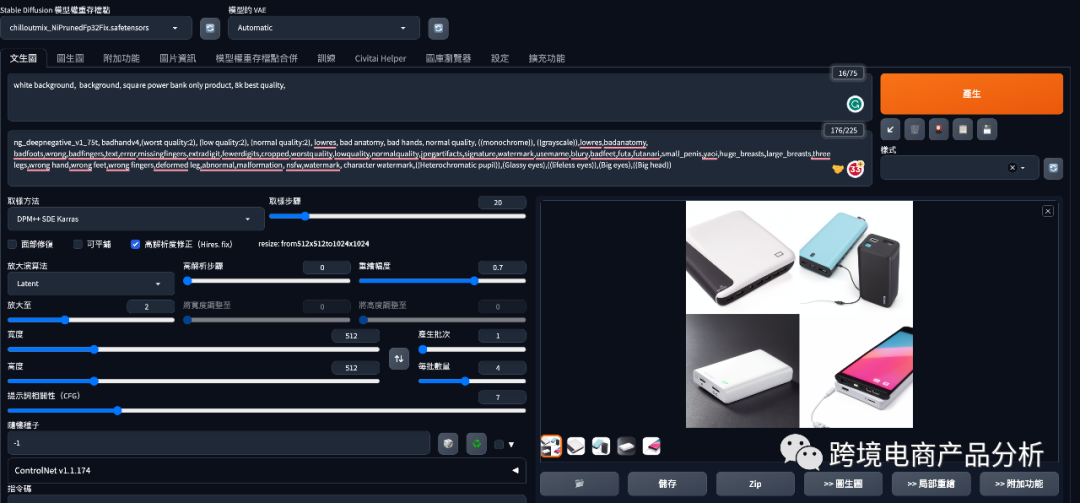
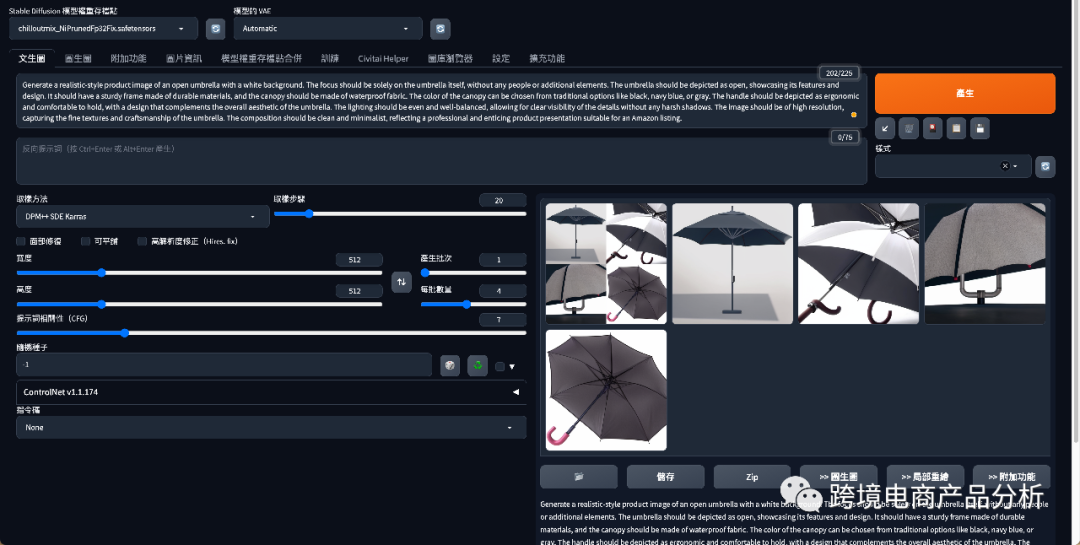
使用Stable Diffusion图像生成优化图片
我们将刚刚生成的图片上传到图像生成界面中,结合具体的产品。由于雨伞需要配合人物或场景展示,所以我直接使用了图像生成的功能,没有使用Canny模型定位雨伞的线稿。提示词是从Civitai站点找到的一张图的正反向prompt,直接复制过来,没有做任何修改。可以看到,图中已经生成了模特拿着伞的图片,右上角的图片基本上还原了产品图片,并配上了模特。如果需要更精细的图片,还需要不断的刷图和微调。
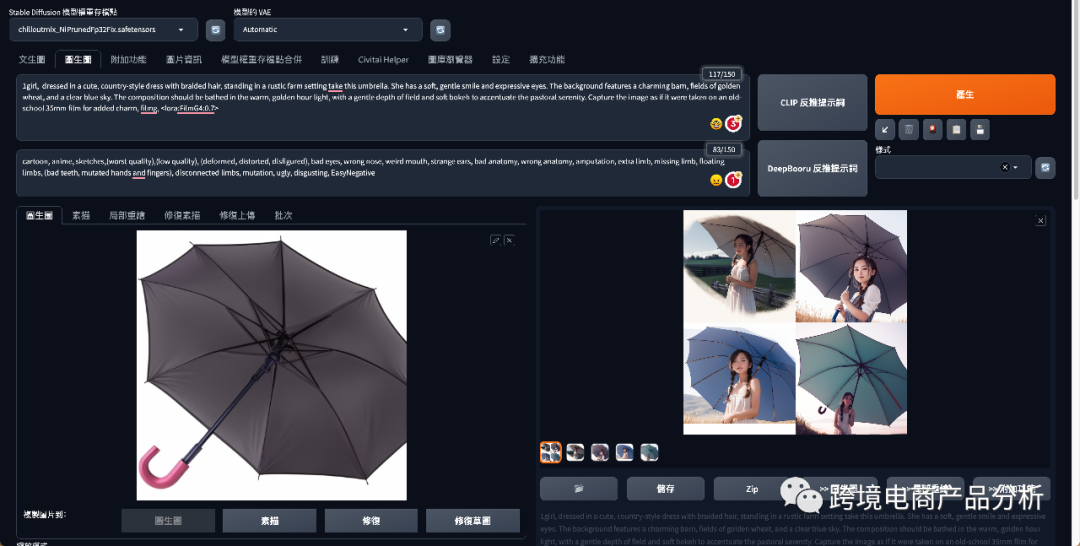
使用ControlNet的Canny模型生成线稿图
另一个产品是充电宝,它本身可以单独展示,不需要借助模特,所以我选择使用ControlNet的Canny模型先框定线稿,再使用简单的prompt更换背景。Prompt部分相对简单,只是简单地写了个背景描述,没有做更多的补充。采样调为DPM++ SDE Karras,重绘程度调到了0.9,这也导致了图像生成后,产品和真实产品有一点出入。ControlNet部分也只是打开了效果,其他参数没有做过多的调整。
可以看出,图片生成后变成了黄色的,这是因为我增大了重绘的效果,想测试这个参数对图片生成的影响。由于Canny模型限制了产品的轮廓,所以导致产品颜色发生变化,但外形几乎没有变化。图片整体看起来很自然,产品突出,显得高端。在实际操作过程中,我们应该先使用Canny模型框定产品轮廓,再结合参数微调,结合适当的提示词,达到更换产品背景的效果。
修改背景和添加文字
最后,我们可以根据销售场景和目标消费者的喜好,使用Photoshop添加文字,完成图片的最终优化。从整个过程来看,这大大减轻了设计师的压力,提高了工作效率,将枯燥的任务交给AI处理,可以创造出意想不到的效果。
思考:我并没有对其他参数进行更多的调试,没有生成出特别惊艳的图片,这部分可以改进。同时,我只使用了一个 ControlNet的模型,如果能够结合 Open Pose模型,可以实现模特换脸等更多玩法,我会在后面的尝试中继续探索。
这篇文章的目的并不是为了生成可以直接用于亚马逊的图片,而是为了展示一种思路。使用AI生成图像本身就需要不断的尝试和调整,而Stable Diffusion则提供了更强大的图片控制能力。我只是抛砖引玉,希望能引发更多的讨论和思考。




























