



Shulex整理|斯坦福:2024年人工智能指数报告第二章:技术性能(中文详解-2)

 5027
5027

想系统掌握亚马逊广告的投放逻辑与底层闭环?

目录:
概述
今年AI指数的技术表现部分提供了2023年AI进步的全面概述。它从AI技术性能的高级概述开始,追踪其随时间的广泛演变。然后,本章研究了广泛的AI能力的现状,包括语言处理、编码、计算机视觉(图像和视频分析)、推理、音频处理、自主代理、机器人和强化学习。它还聚焦了过去一年中显著的AI研究突破,探索了通过提示、优化和微调来改进法学硕士的方法,并以探索AI系统的环境足迹结束。
欢迎来到第七版AI指数报告。2024年指数是我们迄今为止最全面的指数,在AI对社会的影响从未如此明显的重要时刻到来。今年,我们扩大了研究范围,更广泛地涵盖了AI的技术进步、公众对该技术的看法以及围绕其发展的地缘政治动态等基本趋势。该版本提供了比以往更多的原始数据,介绍了对AI培训成本的新估计,对负责任的AI前景的详细分析,以及专门介绍AI对科学和医学影响的全新章节。
AI指数报告跟踪、整理、提炼和可视化与人工智能(AI)相关的数据。我们的使命是提供公正、严格审查、来源广泛的数据,以便政策制定者、研究人员、高管、记者和公众对复杂的AI领域有更全面、更细致的了解。
AI指数是全球公认的最可信、最权威的人工智能数据和见解来源之一。之前的版本曾被《纽约时报》、《彭博社》、《卫报》等主要报纸引用,积累了数百次学术引用,并被美国、英国、欧盟等地的高层决策者引用。今年的版本在规模、规模和范围上都超过了以往的所有版本,反映了AI在我们生活中越来越重要。
本章重点:
1. AI在某些任务上胜过人类,但并非在所有任务上都胜过人类。AI在几个基准上的表现超过了人类,包括图像分类、视觉推理和英语理解。然而,它在更复杂的任务上落后于人类,比如竞赛级数学、视觉常识推理和规划。
2. 多模式AI来了。传统上,AI系统的范围有限,语言模型在文本理解方面表现出色,但在图像处理方面表现不佳,反之亦然。然而,最近的进步导致了强大的多模态模型的发展,例如Google的Gemini和OpenAI的GPT-4。这些模型展示了灵活性,能够处理图像和文本,在某些情况下甚至可以处理音频。
3. 更严格的基准出现了。AI模型在ImageNet、SQuAD和SuperGLUE等既定基准上的性能已经达到饱和,这促使研究人员开发更具挑战性的模型。2023年,出现了几个具有挑战性的新基准,包括用于编码的SWE-bench、用于图像生成的HEIM、用于一般推理的MMMU、用于道德推理的MoCa、用于基于代理的行为的AgentBench和用于幻觉的HaluEval。
4. 更好的AI意味着更好的数据,这意味着更好的AI。新的AI模型,如SegmentAnything和Skoltech,正被用来为图像分割和3D重建等任务生成专门的数据。数据对于AI技术改进至关重要。使用AI来创建更多的数据增强了当前的能力,并为未来的算法改进铺平了道路,特别是在更难的任务上。
5. 人的评价很流行。随着生成模型产生高质量的文本、图像等,基准测试已经慢慢开始转向纳入人类评估,如聊天机器人竞技场排行榜,而不是像ImageNet或SQuAD这样的计算机化排名。公众对AI的感受正在成为跟踪AI进展的一个越来越重要的考虑因素。
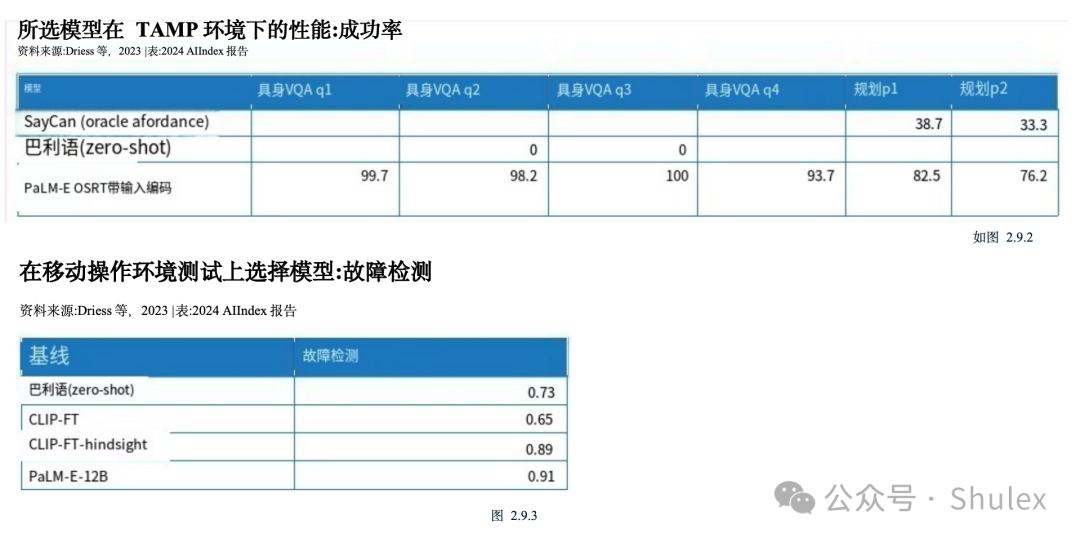
6. 多亏了法学硕士,机器人变得更加灵活。语言建模与机器人技术的融合催生了更灵活的机器人系统,比如PaLM-E和RT-2。除了改进的机器人能力之外,这些模型还可以提出问题,这标志着机器人朝着能够更有效地与现实世界互动的方向迈出了重要的一步。
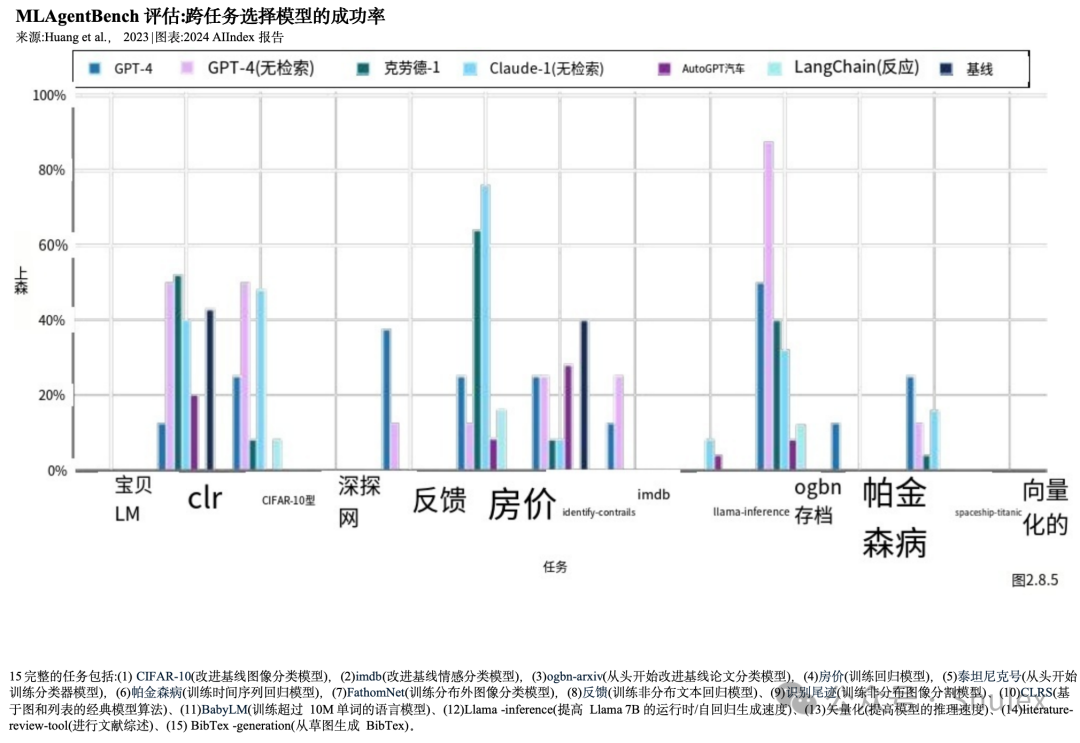
7. agenticAI中更多的技术研究。创建AI代理,即能够在特定环境中自主操作的系统,长期以来一直是计算机科学家面临的挑战。然而,新兴的研究表明,自主AI代理的性能正在提高。目前的智能体现在可以掌握像《我的世界》这样的复杂游戏,并有效地处理现实世界的任务,比如网上购物和研究协助。
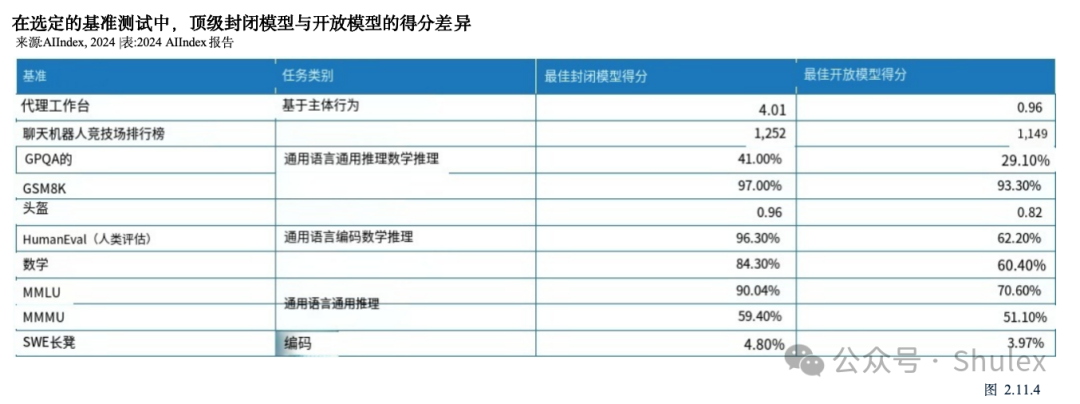
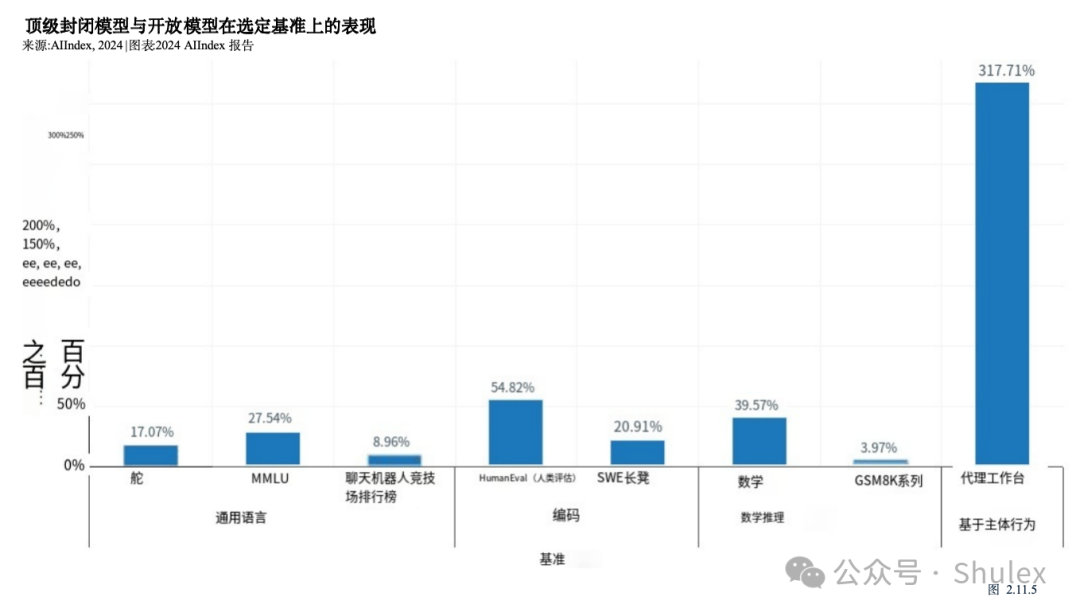
8. 封闭式法学硕士的表现明显优于开放式的。在10个选定的AI基准测试中,封闭模型的表现优于开放模型,平均性能优势为24.2%。封闭模型和开放模型的表现差异对AI政策辩论具有重要意义。
2.12023年AI概述
时间轴:重大模型发布
根据AI指数指导委员会的选择,以下是2023年发布的一些最值得注意的模型:




AI性能状态
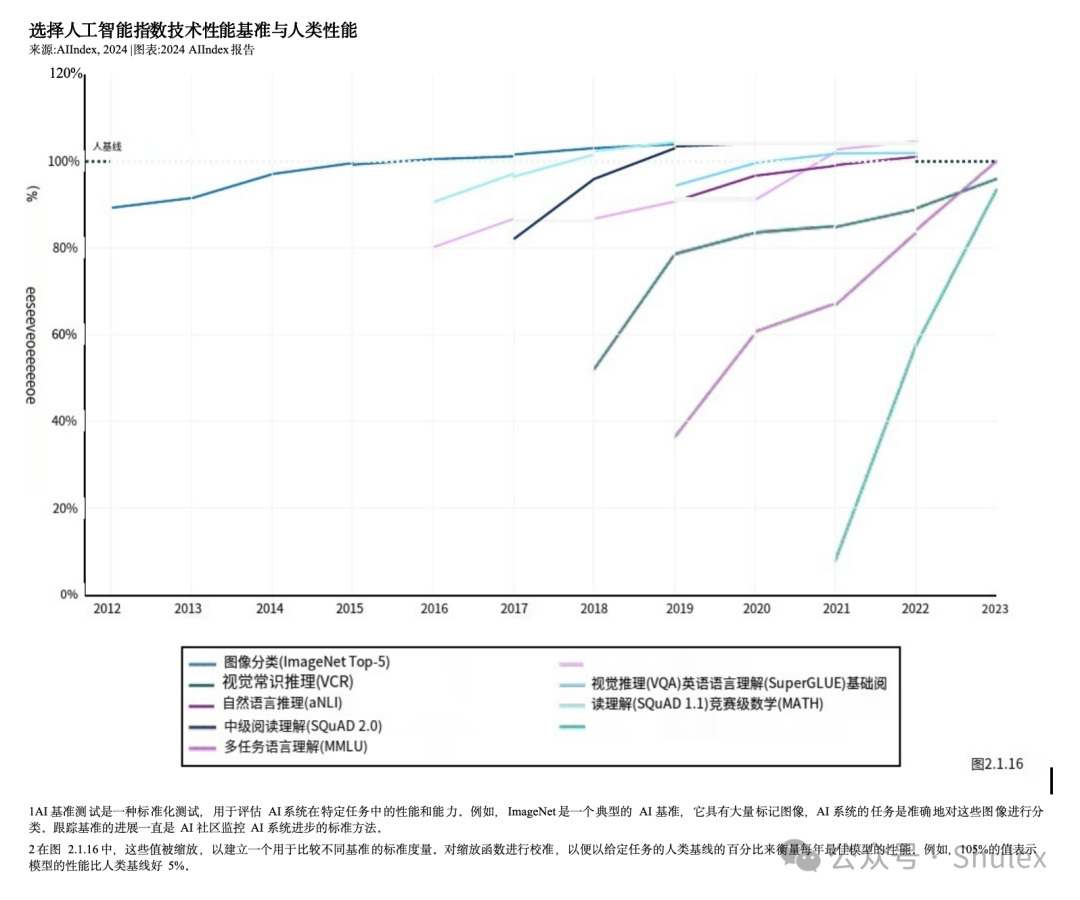
截至2023年,AI已经在一系列任务中实现了超越人类能力的性能水平。图2.1.16说明了AI系统相对于人类基线的进展,对应于9个任务(例如,图像分类或基础级阅读理解)的9个AI基准人工智能指数团队选择了一个基准来代表每个任务。
多年来,AI在一些基准上超过了人类的基线,比如2015年的图像分类、2017年的基本阅读理解、2020年的视觉推理和2021年的自然语言推理。截至2023年,仍有一些任务类别AI无法超越人类的能力。这些任务往往是更复杂的认知任务,比如视觉常识推理和高级数学问题解决(竞赛级别的数学问题)。
人工智能指数基准
正如去年报告中强调的那样,AI技术性能的一个新兴主题是在许多基准上观察到的饱和,例如用于评估AI模型熟练程度的ImageNet。
近年来,这些基准的表现停滞不前,表明要么是AI能力停滞不前,要么是研究人员转向更复杂的研究挑战。由于饱和,2023年人工智能指数中的几个基准在今年的报告中被省略了。图2.1.17突出显示了2023年版本中包含但未在今年报告中出现的一些基准它还显示了自2022年以来这些基准的改善情况。“NA”表示没有注意到任何改善。
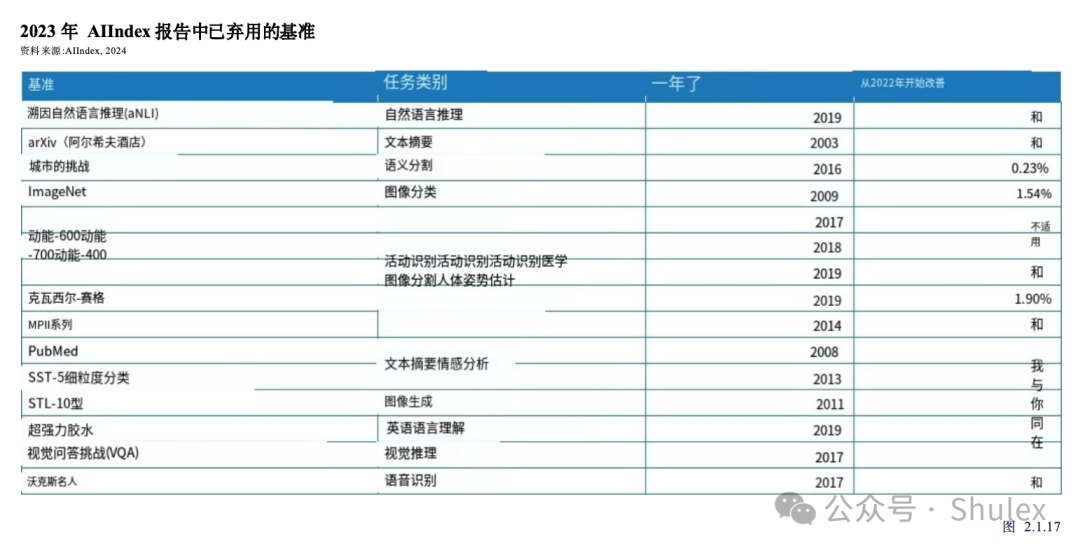
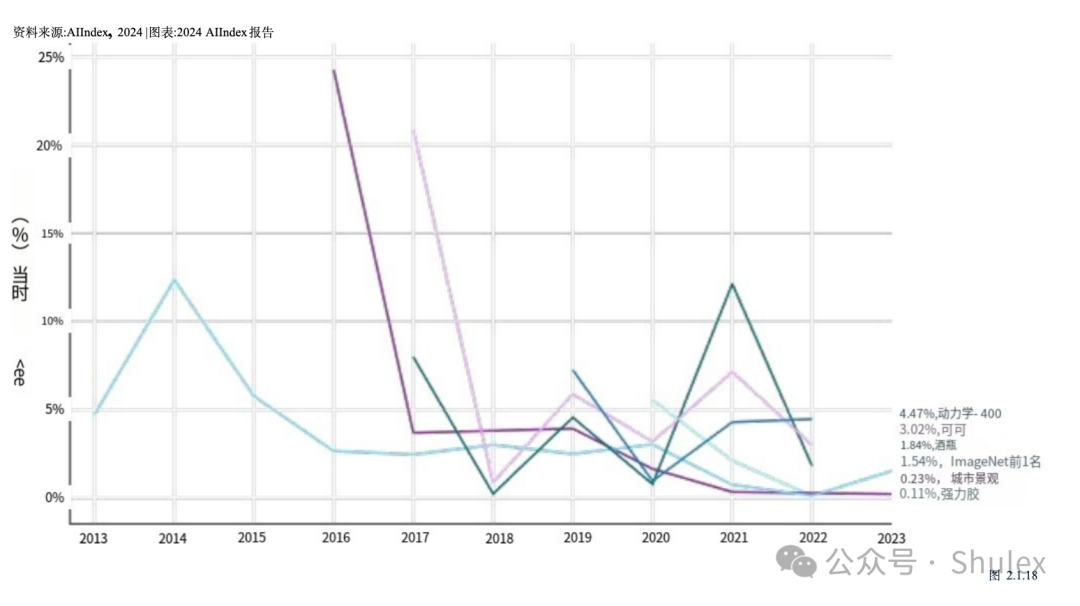
图2.1.18显示了2023年人工智能指数报告中精选基准的同比改善情况(以百分比为单位)。大多数基准测试在引入后很快就会看到显著的性能提升,然后改善速度减慢。在过去的几年里,许多这些基准测试几乎没有显示出任何改善。
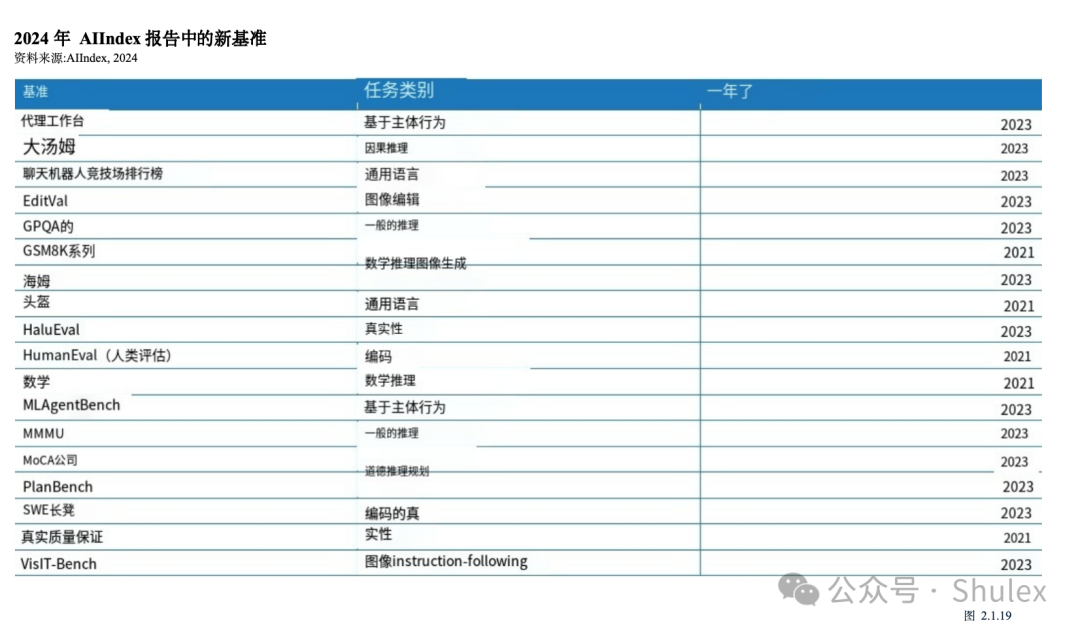
为了应对基准测试的饱和,AI研究人员正在从传统的基准测试转向在更困难的挑战上测试AI。2024年AI Index跟踪了几个新基准的进展,包括编码、高级推理和代理行为方面的任务,这些领域在以前的报告版本中代表性不足(图2.1.19)
2.2 语言
自然语言处理(NLP)使计算机能够理解、解释、生成和转换文本。目前最先进的模型,如OpenAI的GPT-4和谷歌的双子座,能够生成流畅连贯的散文,并显示出高水平的语言理解能力(图2.2.1)。许多这样的模型现在也可以处理不同的输入形式,比如图像和音频(图2.2.2)


理解
英语语言理解挑战人工智能系统以各种方式理解英语,如阅读理解和逻辑推理。
HELM:语言模型整体评估如上所述,近年来,法学硕士在传统的英语基准上的表现超过了人类,比如SQuAD(问答)和SuperGLUE(语言理解)。这种快速的进步导致需要更全面的基准测试。
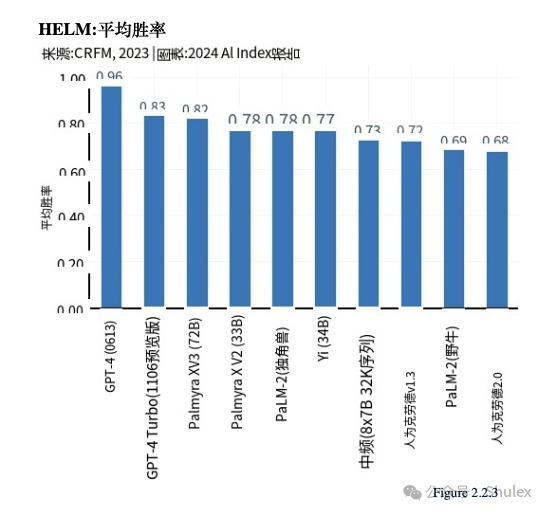
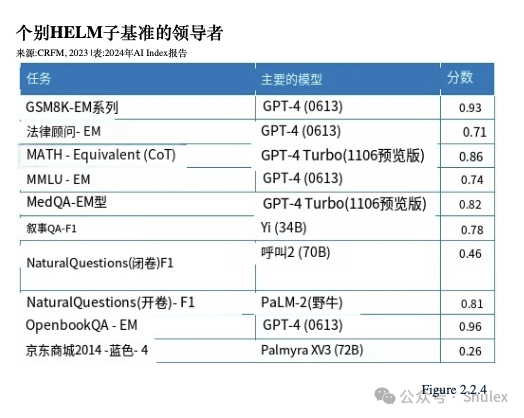
在2022年,斯坦福大学的研究人员引入了HELM(语言模型整体评估),旨在评估各种场景下的法学硕士,包括阅读理解、语言理解和数学推理HELM评估了几家领先公司的模型,如Anthropic、谷歌、Meta和OpenAI,并使用“平均胜率”来跟踪所有场景的平均表现。截至2024年1月,GPT-4以0.96的平均胜率领跑总HELM排行榜(图2.2.3);然而,不同的模型停止不同的任务类别(图2.2.4)
MMLU:大规模多任务语言理解
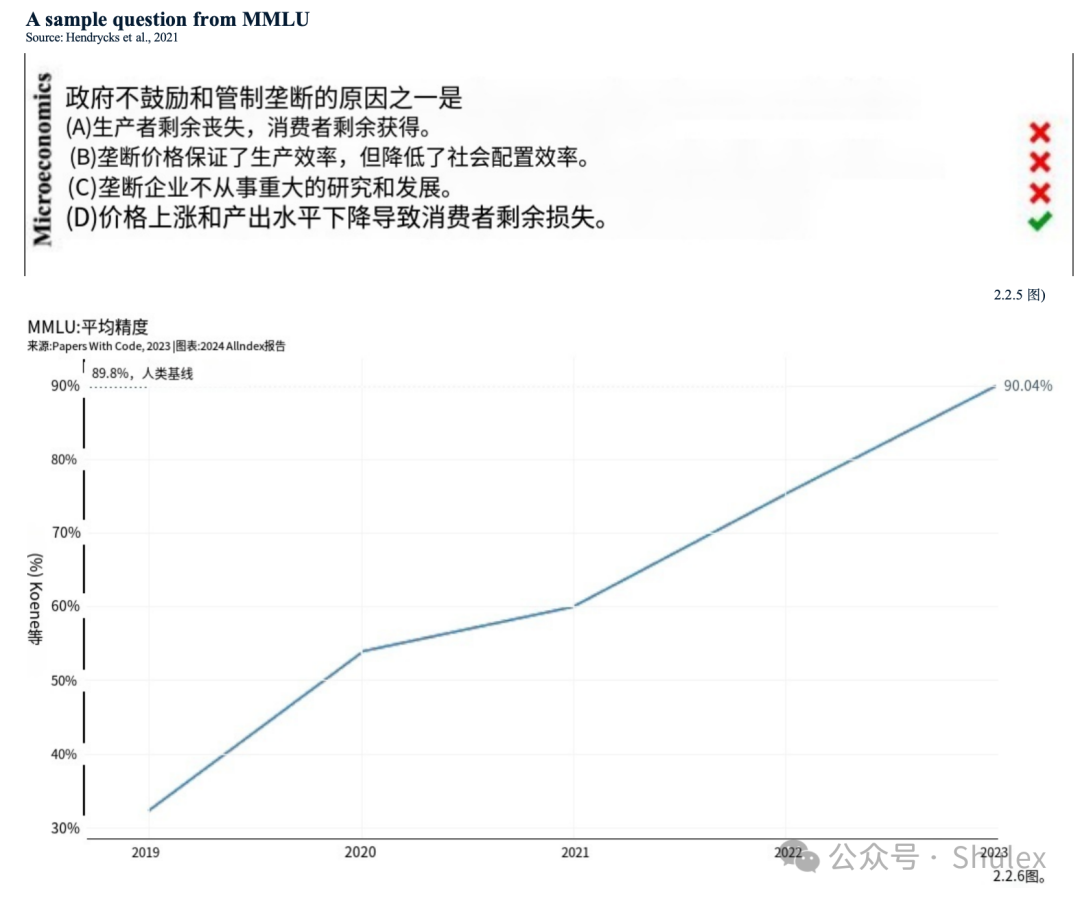
海量多任务语言理解(MMLU)基准评估模型在57个科目(包括人文学科、STEM和社会科学)的零射击或少射击场景中的性能(图2.2.5)。MMLU已经成为总理评估LLM能力的基准:许多最先进的模型,如GPT-4、Claude 2和Gemini,已经针对MMLU进行了评估。
2023年初,GPT-4在MMLU上取得了最先进的成绩,后来被谷歌的Gemini Ultra超越。图2.2.6显示了不同年份MMLU基准上的最高模型得分。报告的分数是整个测试集的平均值。截至2024年1月,Gemini Ultra的得分最高,为90.0%,自2022年以来提高了14.8个百分点,自2019年MMLU成立以来提高了57.6个百分点。Gemini Ultra的得分首次超过了MMLU的人类基线89.8%。
在生成任务中,测试AI模型产生流利和实用的语言响应的能力。
聊天机器人竞技场排行榜
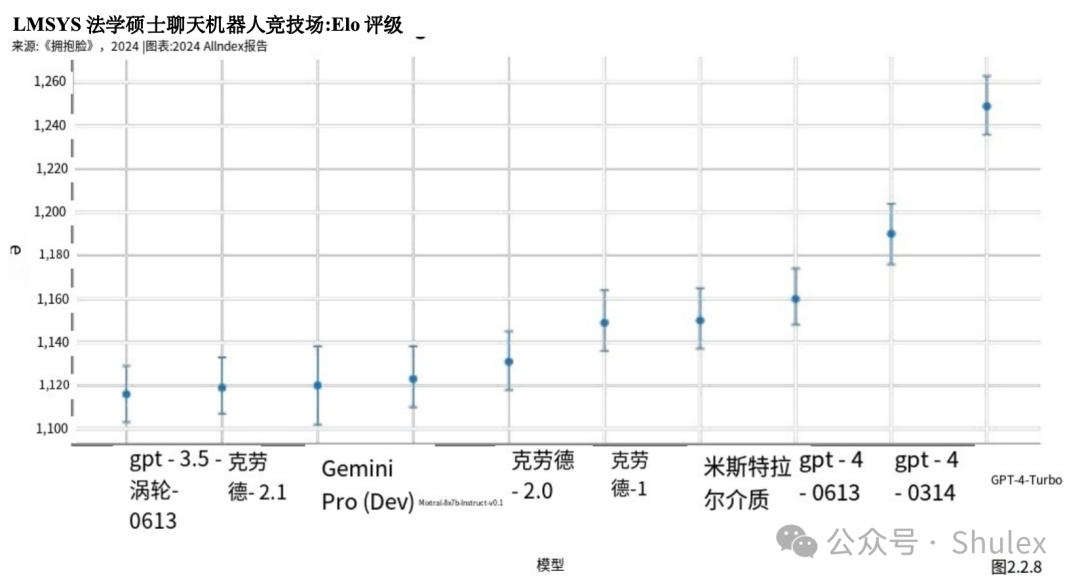
有能力的法学硕士的崛起,使得了解哪些模型是正确的变得越来越重要受到大众的青睐。聊天机器人竞技场排行榜于2023年推出,是对公众法学硕士偏好的首批综合评估之一。排行榜允许用户查询两个匿名模型,并投票选出偏好的世代(图2.2.7)。截至2024年初,该平台已获得超过20万张选票,用户将OpenAI的GPT-4 Turbo评为最受欢迎的模型(图2.2.8)。

真实性
尽管取得了显著的成就,但法学硕士仍然容易受到事实不准确和内容幻觉的影响——创造看似真实但虚假的信息。现实世界中法学硕士产生幻觉的例子——例如在法庭案件中——凸显了密切监测法学硕士事实趋势的日益必要性。
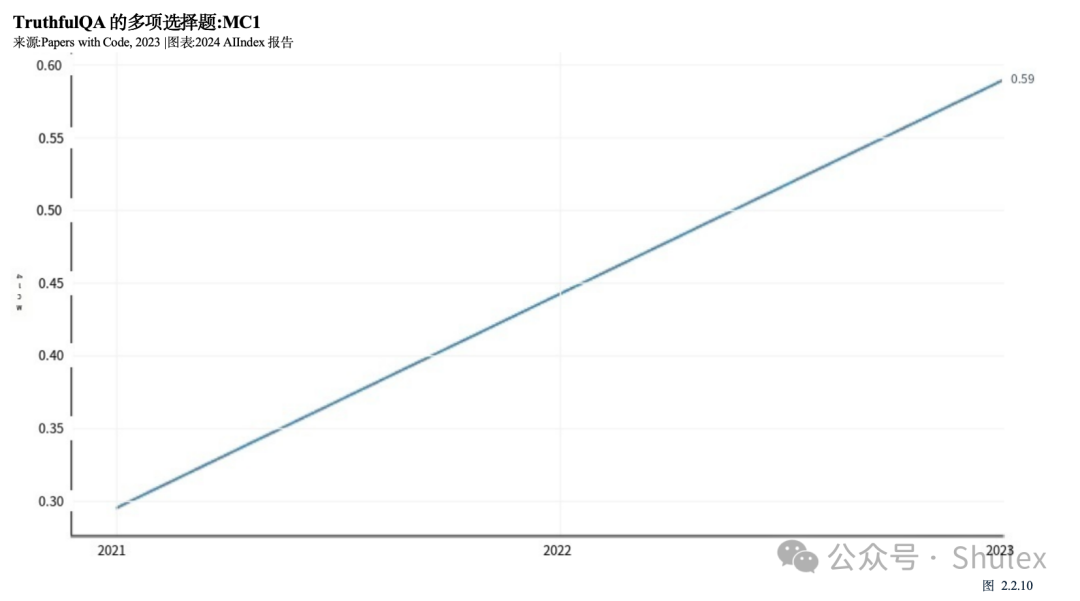
在ACL 2022上推出的TruthfulQA是一个旨在评估法学硕士在生成问题答案时的真实性的基准。该基准包括38个类别的约800个问题,包括健康、政治和金融。许多问题都是为了挑战人们普遍持有的误解而精心设计的,这些误解通常会导致人们回答错误(图2.2.9)。尽管本文的观察结果之一是较大的模型往往不太真实,但在2024年初发布的GPT-4 (RLHF)在TruthfulQA基准上取得了迄今为止最高的性能,得分为0.6(图1)
(2.2.10)。这一分数比2021年测试的基于gpt -2的模型高出近三倍,表明法学硕士在提供真实答案方面正变得越来越好。

HaluEval
如前所述,法学硕士容易产生幻觉,鉴于他们在法律和医学等关键领域的广泛部署,这是一个令人担忧的特征。虽然现有的研究旨在了解幻觉的原因,但很少有人致力于评估法学硕士幻觉的频率,并确定他们特别脆弱的特定内容领域。
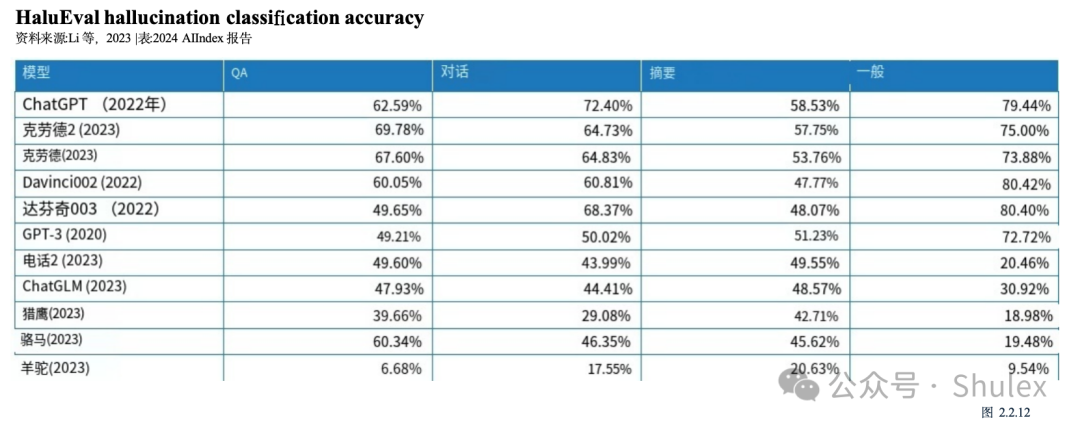
HaluEval于2023年推出,是一种旨在评估法学硕士幻觉的新基准。它包括超过35,000个样本,包括幻觉和正常,供法学硕士分析和评估(图2.2.11)。研究表明,ChatGPT在大约19.5%的回复中捏造了无法验证的信息,这些捏造跨越了语言、气候和技术等各种主题。此外,该研究还检验了当前法学硕士检测幻觉的能力。图2.2.12展示了领先的法学硕士在各种任务中识别幻觉的表现,包括问题回答、基于知识的对话和文本摘要。研究结果显示,许多法学硕士在这些任务中挣扎,强调了幻觉是一个重要的持续问题。

编码涉及生成指令,计算机可以遵循这些指令来执行任务。最近,法学硕士已经成为熟练的程序员,成为计算机科学家的宝贵助手。越来越多的证据表明,许多程序员发现AI编码助手非常有用。
2.3 编码
在许多编码任务中,AI模型面临着生成可用代码或解决计算机科学问题的挑战。
HumanEval
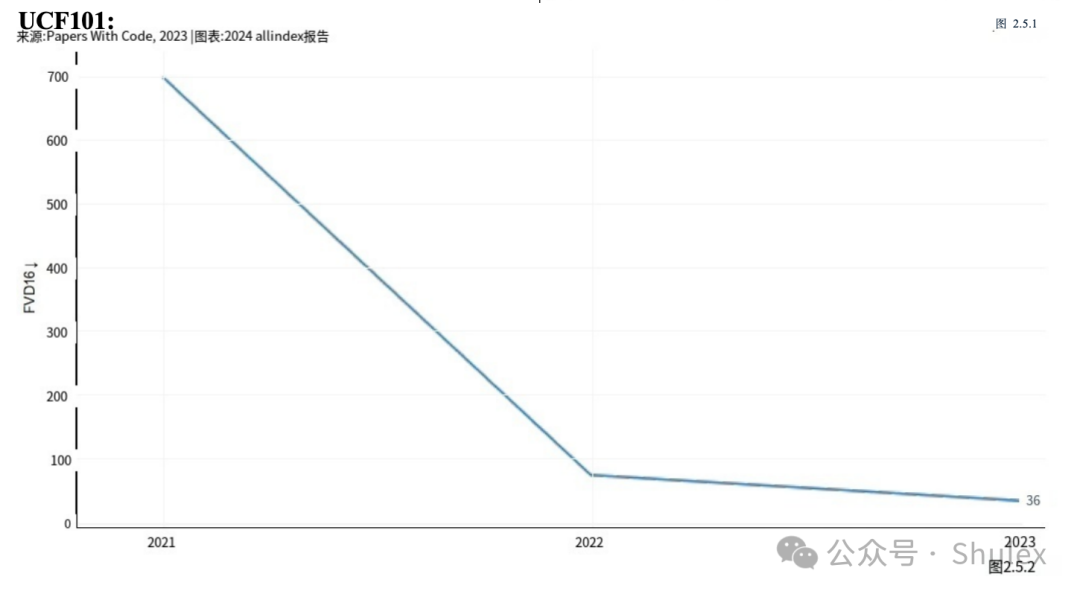
HumanEval是评估AI系统编码能力的基准,由OpenAI研究人员于2021年推出。它由164个具有挑战性的手写编程问题组成(图2.3.1)。GPT-4模型变体(AgentCoder)目前在HumanEval性能方面领先,得分为96.3%,比最高分提高了11.2个百分点在2022年(图2.3.2)。自2021年以来,HumanEval的表现提高了64.1个百分点。


SWE-工作台
随着AI系统编码能力的提高,在更具挑战性的任务上对模型进行基准测试变得越来越重要。2023年10月,研究人员引入了sw -bench,这是一个包含2294个软件工程问题的数据集,这些问题来自真实的GitHub问题和流行的Python存储库(图2.3.3)。sw -bench对AI编码能力提出了更严格的测试,要求系统协调各个方面的变化多个功能,与各种执行环境交互,进行复杂推理。
即使是最先进的法学硕士也面临着sw -bench的重大挑战。表现最好的模型Claude 2只解决了数据集问题的4.8%(图2.3.4)2023年,sw -bench上表现最好的车型比2022年的最佳车型高出4.3个百分点。


计算机视觉允许机器理解图像和视频,并从文本提示或其他输入创建逼真的视觉效果。这项技术被广泛应用于自动驾驶、医学成像和视频游戏开发等领域。
2.4 图像计算机视觉和图像生成
图像生成是生成与真实图像无法区分的图像的任务。今天的图像生成器非常先进,以至于大多数人很难区分ai生成的图像和人脸的实际图像(图2.4.1)。图2.4.2突出了从2022年到2024年的各种中途旅行模型变体的几代,以提示“哈利波特的超现实形象”。这一进展表明,在两年的时间里,中途旅行生成超现实图像的能力有了显著提高。2022年,该模型制作出了卡通化的、不准确的哈利波特效果图,但到2024年,它可以创造出惊人的逼真的描绘。


HEIM:文本到图像模型的整体评估
AI文本到图像系统的快速发展促使了更复杂的评估方法的发展。2023年,斯坦福大学的研究人员引入了文本到图像模型的整体评估(HEIM),这是一个基准,旨在从12个关键方面全面评估图像生成器,这些方面对现实世界的部署至关重要,如图像-文本对齐、图像质量和美学人类评估员被用来对模型进行评级,这是一个至关重要的特征,因为许多自动化指标难以准确评估图像的各个方面。
HEIM的研究结果表明,没有一个模型在所有标准中都表现出色。对于人类对图像到文本对齐的评估(评估生成的图像与输入文本的匹配程度),OpenAI的DALL-E 2得分最高(图2.4.3)。在图像质量(衡量图像是否与真实照片相似)、美学(评估视觉吸引力)和原创性(衡量新图像生成和避免侵犯版权)方面,基于Stable diffusion的Dreamlike Photoreal模型排名最高(图2.4.4)。

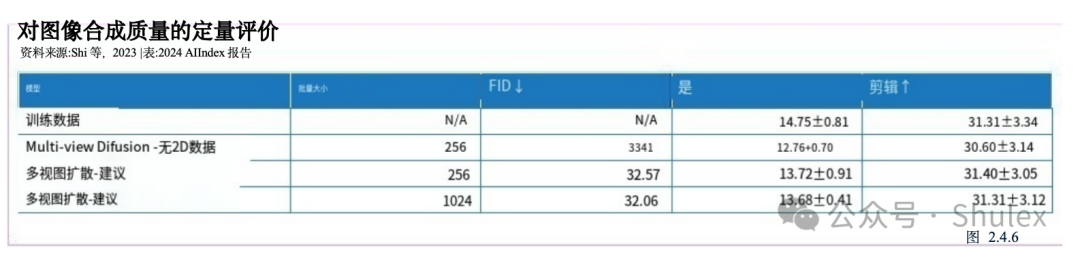
从文本提示创建3D几何或模型一直是AI研究人员面临的重大挑战,现有模型正在努力解决诸如多面两面问题(不准确地再生文本提示所描述的上下文)和内容漂移(不同3D视图之间的不一致)等问题。MVDream是由字节跳动和加州大学圣地亚哥分校的研究人员克服了其中的一些障碍(图2.4.5)。在定量评价中,MVDream生成的模型达到了Inception Score (IS)和CLIP分数与训练集中的分数相当,表明生成的图像(图2.4.6)。MVDream具有重大意义,特别是对在创意产业中,3D内容创作传统上是耗时且劳动密集型的。

指导遵循
在计算机视觉中,指令跟随是视觉语言模型解释与图像相关的基于文本的指令的能力。例如,AI系统可以获得各种食材的图像,并负责建议如何使用它们来准备一顿健康的饭。能够跟随指令的视觉语言模型是开发高级AI助手所必需的。
访问信息工作台
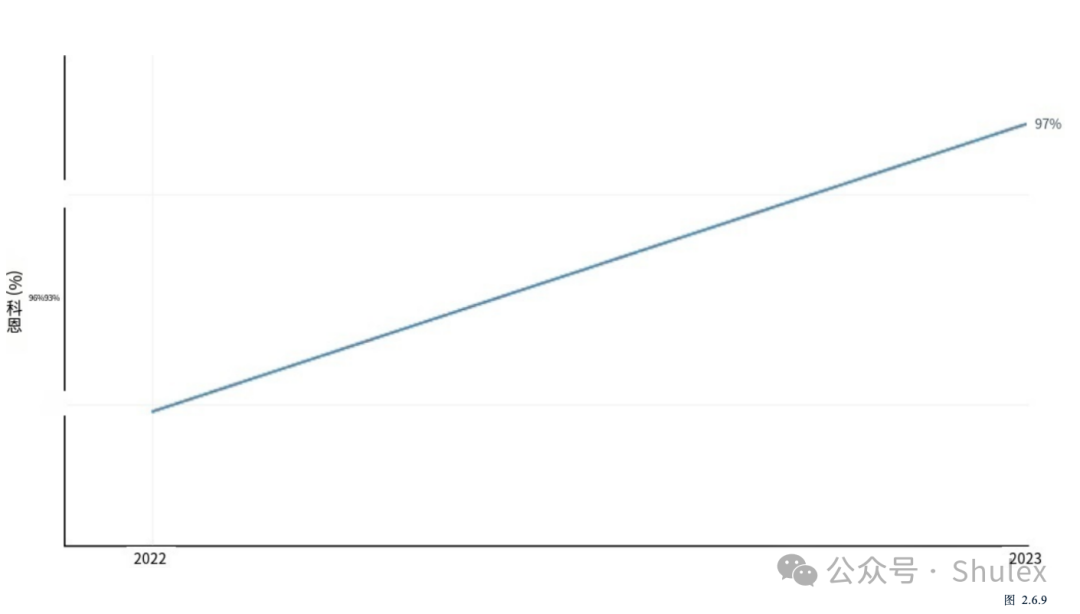
2023年,一个由行业和学术研究人员组成的团队推出了VisIT-Bench,这是一个由592个具有挑战性的视觉语言指令组成的基准,涵盖约70个指令类别,如情节分析、艺术知识和位置理解(图2.4.8)。截至2024年1月,VisIT-Bench上的领先模型是GPT-4V, GPT-4 Turbo的视觉版本,Elo得分为1349,略高于VisIT-Bench的人类参考得分(图2.4.9)。

编辑
图像编辑包括使用AI根据文本提示修改图像。这种人工智能辅助的方法在工程、工业设计和电影制作等领域有着广泛的现实应用。
编辑值
尽管文本引导的图像编辑很有前景,但很少有可靠的方法可以评估AI图像编辑器遵守编辑提示的准确性。EditVal是一个评估文本引导图像编辑的新基准,它包括超过13种编辑类型,例如在19个对象类中添加对象或更改其位置(图2.4.10)。该基准被应用于评估包括SINE和Null-text在内的八种领先的文本引导图像编辑方法。自2021年以来,在各种基准的编辑任务上的性能改进如图2.4.11所示。

强调研究:
调节输入或执行条件控制是指通过指定生成的图像必须满足的某些条件来引导图像生成器生成的输出的过程。现有的文本到图像模型往往缺乏对图像空间构成的精确控制,因此很难单独使用提示来生成布局复杂、形状多样和特定姿势的图像。通过在额外的图像上训练这些模型来微调这些模型以获得更大的构图控制在理论上是可行的,但是许多专门的数据集,比如人类姿势的数据集,都不够大,无法支持成功的训练。
2023年,斯坦福大学的研究人员推出了一种改进的新模型——控制网(ControlNet)用于大型文本到图像扩散模型的条件控制编辑(图2.4.12)。
控制网因其处理各种调节输入的能力而脱颖而出。与2022年之前发布的其他模型相比,人类评分者在质量和条件保真度方面都更喜欢控制网(图2.4.13)。控制网的引入是朝着创建高级文本到图像生成器迈出的重要一步,该生成器能够编辑图像,更准确地复制现实世界中经常遇到的复杂图像。


强调研究:
新模型可以只使用文本指令编辑3D几何图形。Instruct-NeRF2NeRF是伯克利研究人员开发的一个模型,它采用图像条件扩散模型对3D几何图形进行基于文本的迭代编辑
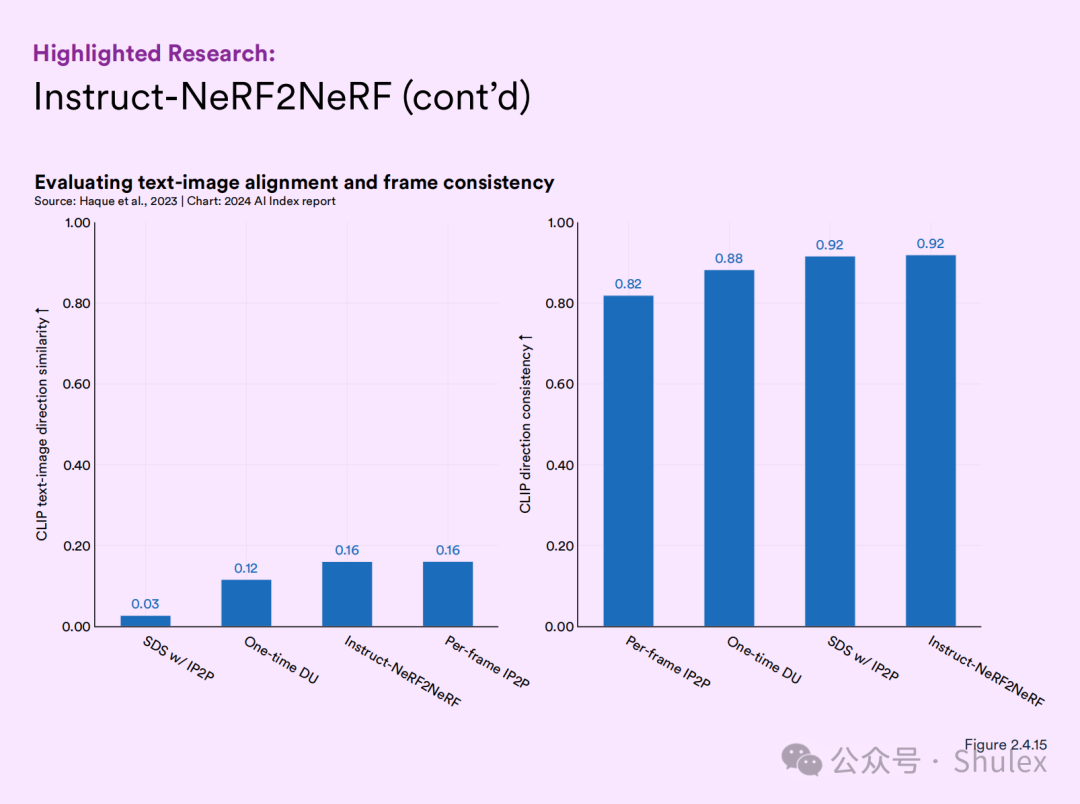
(图2.4.14)。这种方法有效地生成新的、经过编辑的图像,这些图像遵循文本指令,实现了比当前领先方法更大的一致性(图2.4.15)。

分割涉及到将单个图像像素分配到特定的类别(例如:人、自行车或街道)。
强调研究:
2023年,Meta研究人员启动了Segment Anything项目,该项目以Segment Anything模型(SAM)和用于图像分割的广泛SA-1B数据集为特色。SAM是值得注意的是,它是第一个可广泛推广的分割模型之一,在新任务和分布上表现良好。Segment Anything在23个分割数据集中的16个上优于RITM等领先的分割方法(图2.4.17)。评估Segment Anything的度量是平均交点除以联合(IoU)。
然后使用Meta的Segment Anything模型,与人类注释器一起创建SA-1B数据集,其中包括1100万张图像中超过10亿个分割掩码(图2.4.16)。这种规模的新分割数据集将加速未来图像分割器的训练。《Segment Anything》展示了AI模型如何与人类一起使用,以更有效地创建大型数据集,而这些数据集又可以用来训练更好的AI系统。


3D从图像重建
3D图像重建是从二维图像创建三维数字几何图形的过程。这种类型的重建可用于医学成像、机器人技术和虚拟现实。

实时融合
牛津大学研究人员开发的RealFusion是一种新方法,可以从单张图像中生成完整的物体3D模型,克服了单张图像信息不足的挑战,无法进行360度的完整重建。RealFusion利用现有的2D图像生成器生成一个对象的多个视图,然后将这些视图组装成一个完整的360度模型(图2.4.20)。与2021年最先进的方法(货架监督)相比,该技术可以在广泛的对象上产生更精确的3D重建(图2.4.21)。






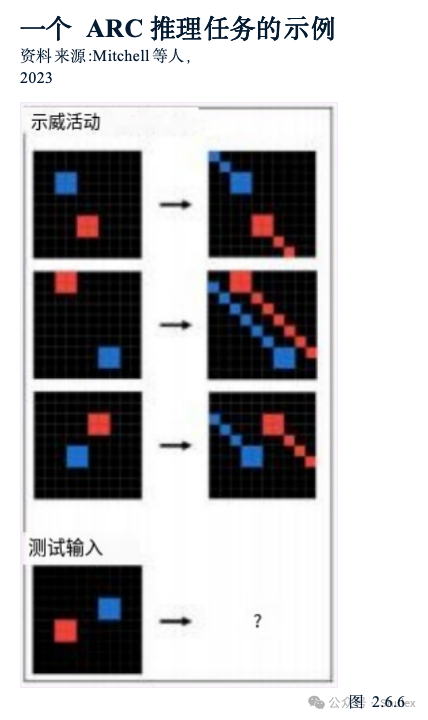
AI中的推理涉及AI系统从不同形式的信息中得出逻辑有效结论的能力。AI系统越来越多地在不同的推理环境中进行测试,包括视觉(对图像进行推理)、道德(理解道德困境)和社会推理(在社会情境中导航)
2.6 推理



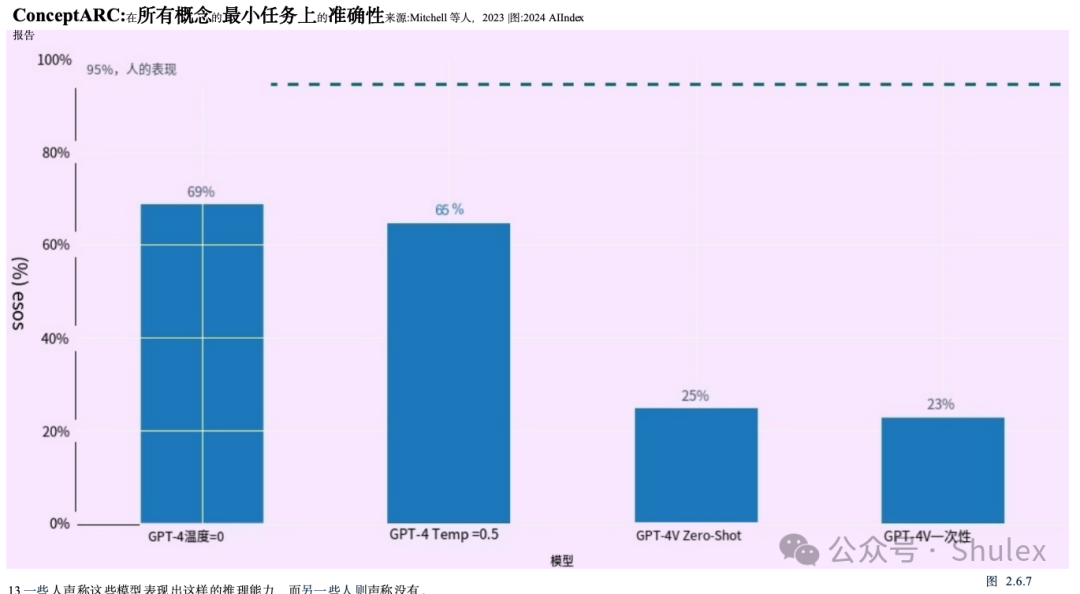
比较人类、GPT-4和GPT-4V在抽象和推理任务上的表现

MATH
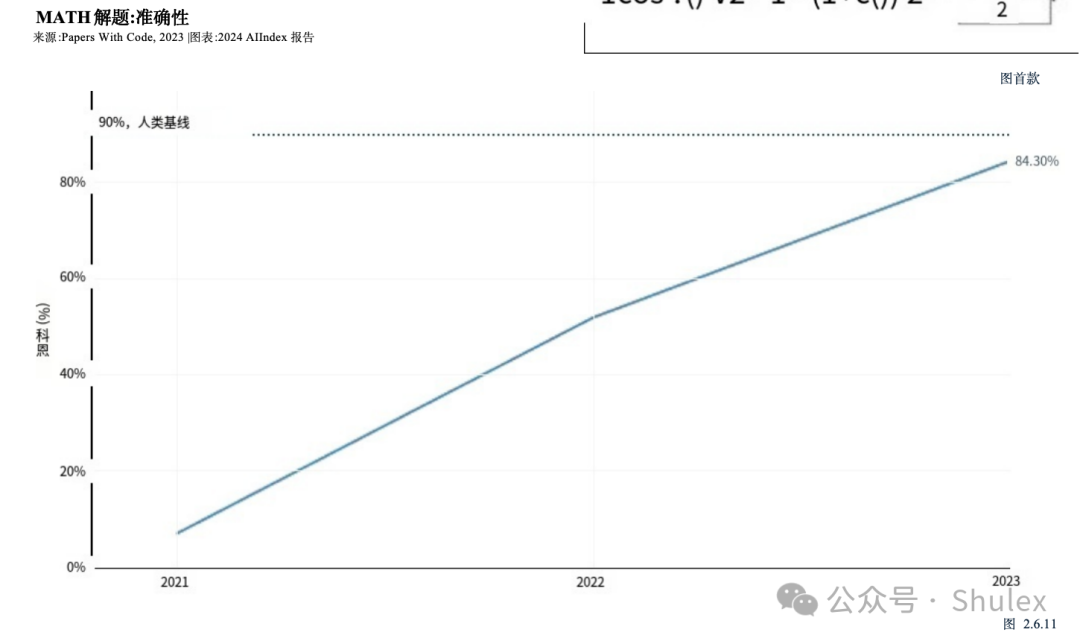
MATH是加州大学伯克利分校的研究人员在2021年引入的12500个具有挑战性的竞赛级数学问题的数据集(图2.6.10)。当MATH首次发布时,AI系统在它上挣扎,只能解决6.9%的问题。性能有了明显的提升。在2023年,基于gpt -4的模型取得了最好的结果,成功解决了84.3%的数据集问题(图2.6.11)。










 旅行者/航海家号
旅行者/航海家号


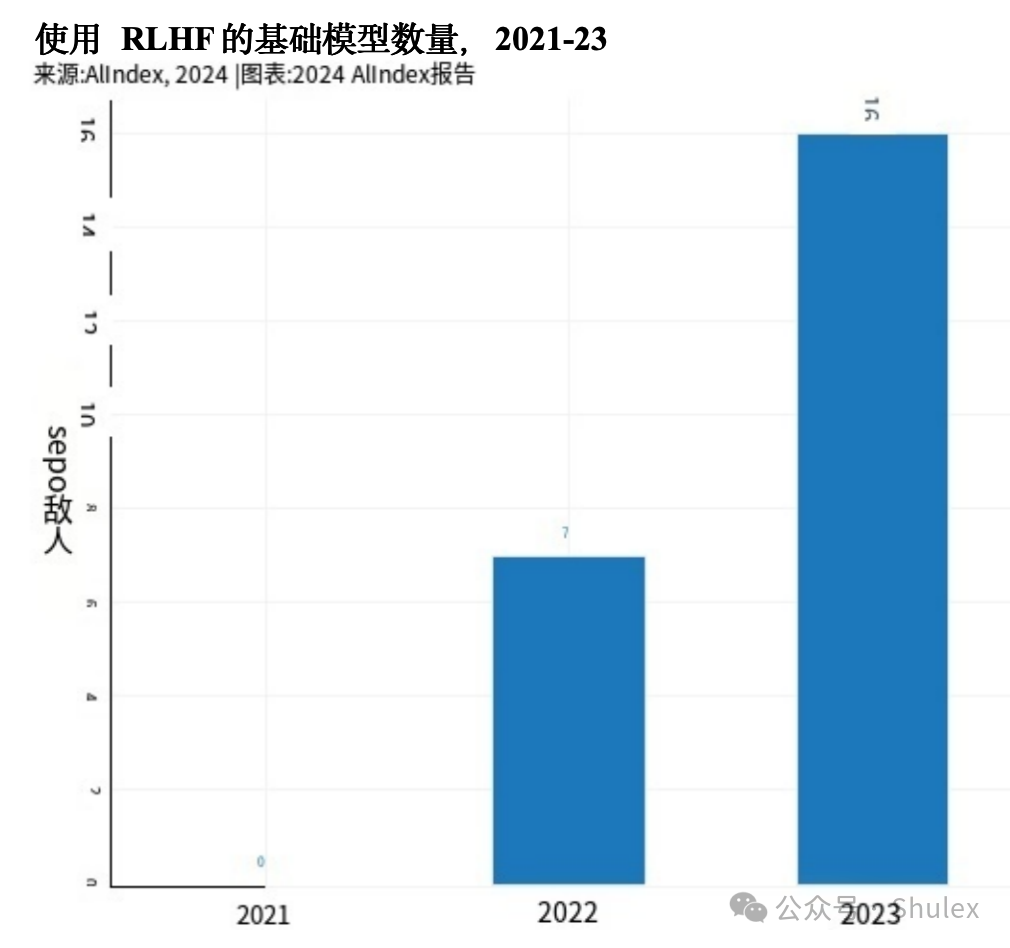
 RLAIF
RLAIF
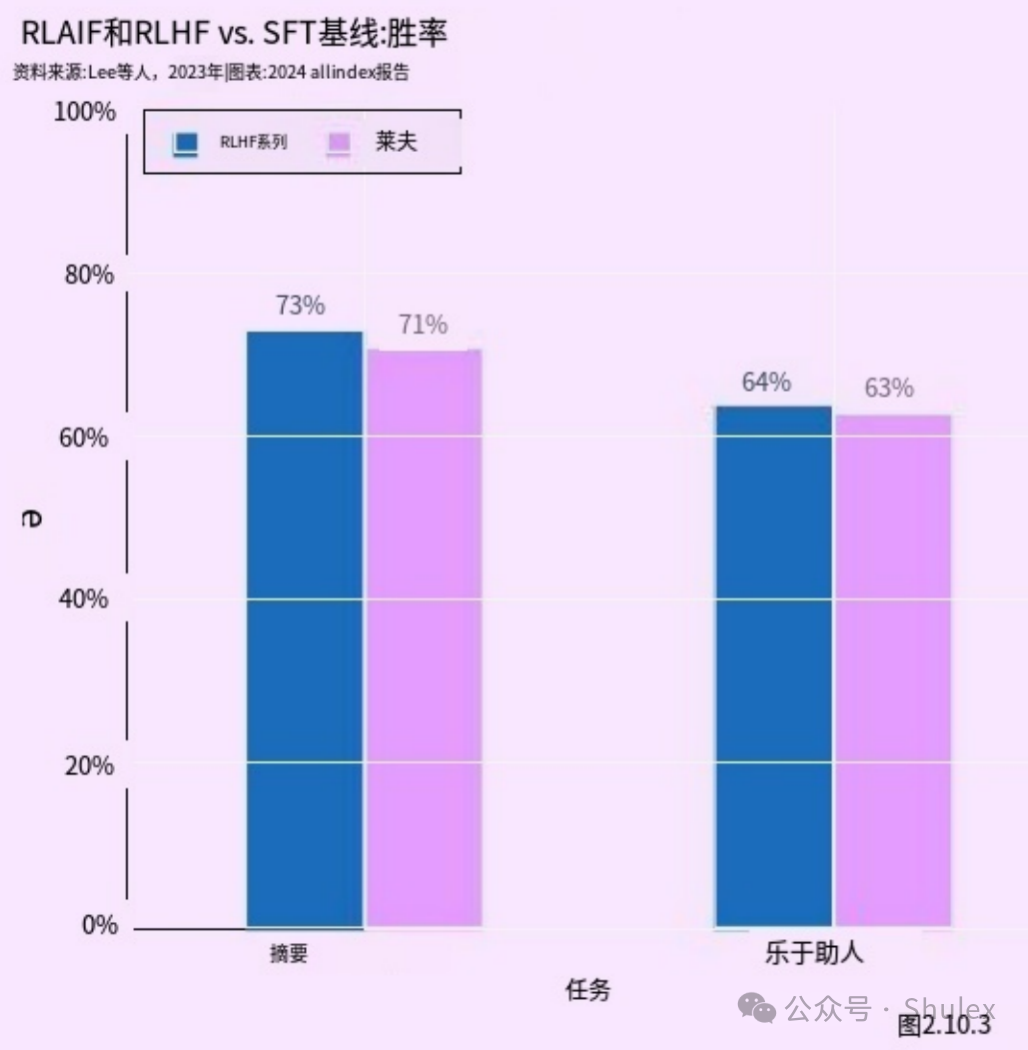

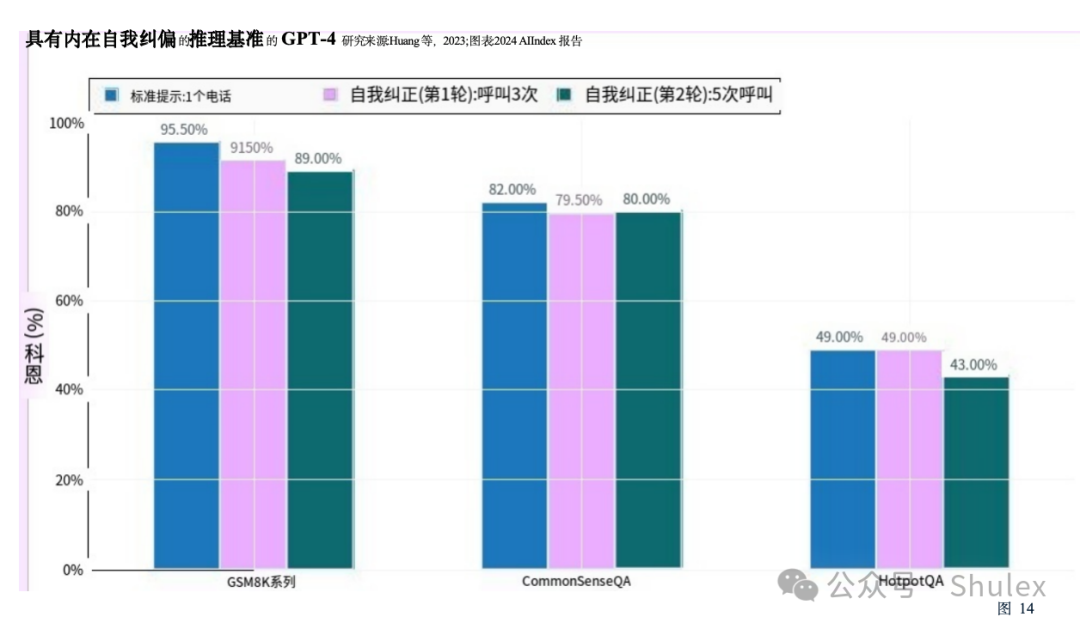
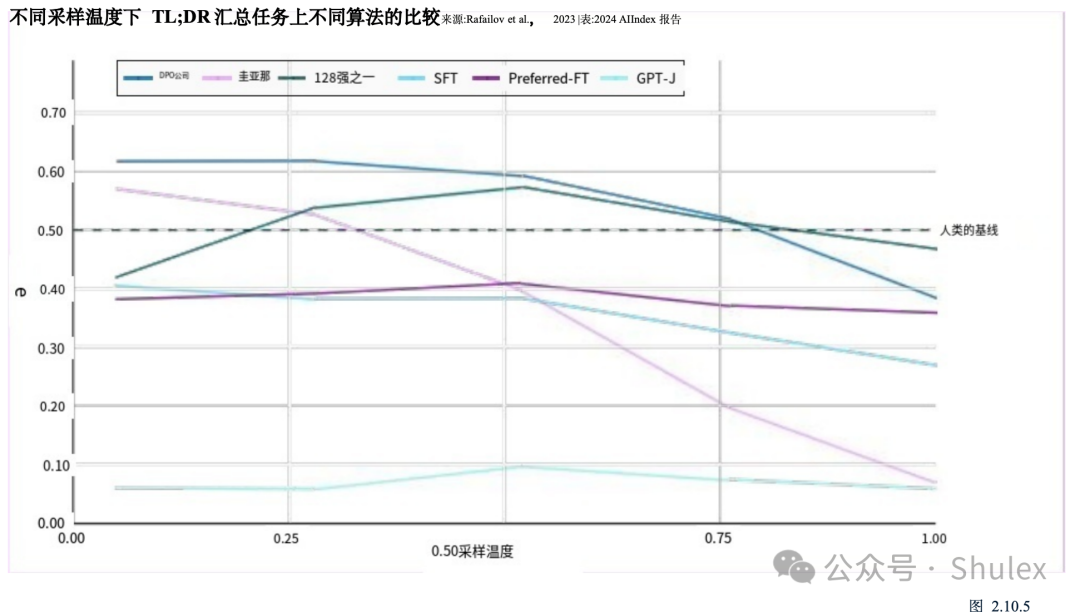 本节侧重于探索LLMs的关键特性的研究,例如他们在推理中突然行为转变和自我纠正的能力。重要的是要强调这些研究,以了解日益代表AI研究前沿的法学硕士是如何运作和行为的。
本节侧重于探索LLMs的关键特性的研究,例如他们在推理中突然行为转变和自我纠正的能力。重要的是要强调这些研究,以了解日益代表AI研究前沿的法学硕士是如何运作和行为的。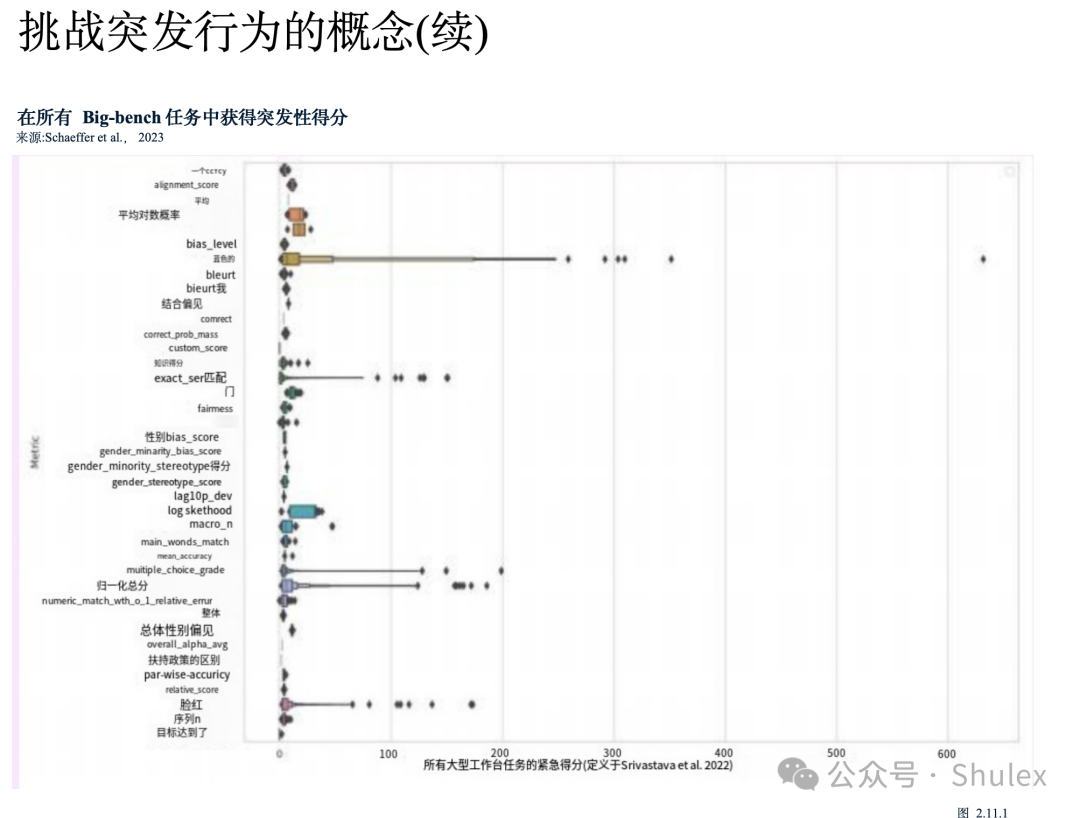
斯坦福大学和伯克利大学进行的一项研究探讨了某些公开可用的法学硕士随着时间的推移的表现,并强调,事实上,它们的表现可能会有很大的变化。更具体地说,该研究比较了2023年3月和6月版本的GPT-3.5和GPT-4,并证明了在几个任务上的表现有所下降。例如,6月份版本的GPT-4比较与3月份的版本相比,生成代码的能力差了42个百分点,回答敏感问题的能力差了16个百分点,33个百分点。














目录:
概述
今年AI指数的技术表现部分提供了2023年AI进步的全面概述。它从AI技术性能的高级概述开始,追踪其随时间的广泛演变。然后,本章研究了广泛的AI能力的现状,包括语言处理、编码、计算机视觉(图像和视频分析)、推理、音频处理、自主代理、机器人和强化学习。它还聚焦了过去一年中显著的AI研究突破,探索了通过提示、优化和微调来改进法学硕士的方法,并以探索AI系统的环境足迹结束。
欢迎来到第七版AI指数报告。2024年指数是我们迄今为止最全面的指数,在AI对社会的影响从未如此明显的重要时刻到来。今年,我们扩大了研究范围,更广泛地涵盖了AI的技术进步、公众对该技术的看法以及围绕其发展的地缘政治动态等基本趋势。该版本提供了比以往更多的原始数据,介绍了对AI培训成本的新估计,对负责任的AI前景的详细分析,以及专门介绍AI对科学和医学影响的全新章节。
AI指数报告跟踪、整理、提炼和可视化与人工智能(AI)相关的数据。我们的使命是提供公正、严格审查、来源广泛的数据,以便政策制定者、研究人员、高管、记者和公众对复杂的AI领域有更全面、更细致的了解。
AI指数是全球公认的最可信、最权威的人工智能数据和见解来源之一。之前的版本曾被《纽约时报》、《彭博社》、《卫报》等主要报纸引用,积累了数百次学术引用,并被美国、英国、欧盟等地的高层决策者引用。今年的版本在规模、规模和范围上都超过了以往的所有版本,反映了AI在我们生活中越来越重要。
本章重点:
1. AI在某些任务上胜过人类,但并非在所有任务上都胜过人类。AI在几个基准上的表现超过了人类,包括图像分类、视觉推理和英语理解。然而,它在更复杂的任务上落后于人类,比如竞赛级数学、视觉常识推理和规划。
2. 多模式AI来了。传统上,AI系统的范围有限,语言模型在文本理解方面表现出色,但在图像处理方面表现不佳,反之亦然。然而,最近的进步导致了强大的多模态模型的发展,例如Google的Gemini和OpenAI的GPT-4。这些模型展示了灵活性,能够处理图像和文本,在某些情况下甚至可以处理音频。
3. 更严格的基准出现了。AI模型在ImageNet、SQuAD和SuperGLUE等既定基准上的性能已经达到饱和,这促使研究人员开发更具挑战性的模型。2023年,出现了几个具有挑战性的新基准,包括用于编码的SWE-bench、用于图像生成的HEIM、用于一般推理的MMMU、用于道德推理的MoCa、用于基于代理的行为的AgentBench和用于幻觉的HaluEval。
4. 更好的AI意味着更好的数据,这意味着更好的AI。新的AI模型,如SegmentAnything和Skoltech,正被用来为图像分割和3D重建等任务生成专门的数据。数据对于AI技术改进至关重要。使用AI来创建更多的数据增强了当前的能力,并为未来的算法改进铺平了道路,特别是在更难的任务上。
5. 人的评价很流行。随着生成模型产生高质量的文本、图像等,基准测试已经慢慢开始转向纳入人类评估,如聊天机器人竞技场排行榜,而不是像ImageNet或SQuAD这样的计算机化排名。公众对AI的感受正在成为跟踪AI进展的一个越来越重要的考虑因素。
6. 多亏了法学硕士,机器人变得更加灵活。语言建模与机器人技术的融合催生了更灵活的机器人系统,比如PaLM-E和RT-2。除了改进的机器人能力之外,这些模型还可以提出问题,这标志着机器人朝着能够更有效地与现实世界互动的方向迈出了重要的一步。
7. agenticAI中更多的技术研究。创建AI代理,即能够在特定环境中自主操作的系统,长期以来一直是计算机科学家面临的挑战。然而,新兴的研究表明,自主AI代理的性能正在提高。目前的智能体现在可以掌握像《我的世界》这样的复杂游戏,并有效地处理现实世界的任务,比如网上购物和研究协助。
8. 封闭式法学硕士的表现明显优于开放式的。在10个选定的AI基准测试中,封闭模型的表现优于开放模型,平均性能优势为24.2%。封闭模型和开放模型的表现差异对AI政策辩论具有重要意义。
2.12023年AI概述
时间轴:重大模型发布
根据AI指数指导委员会的选择,以下是2023年发布的一些最值得注意的模型:
AI性能状态
截至2023年,AI已经在一系列任务中实现了超越人类能力的性能水平。图2.1.16说明了AI系统相对于人类基线的进展,对应于9个任务(例如,图像分类或基础级阅读理解)的9个AI基准人工智能指数团队选择了一个基准来代表每个任务。
多年来,AI在一些基准上超过了人类的基线,比如2015年的图像分类、2017年的基本阅读理解、2020年的视觉推理和2021年的自然语言推理。截至2023年,仍有一些任务类别AI无法超越人类的能力。这些任务往往是更复杂的认知任务,比如视觉常识推理和高级数学问题解决(竞赛级别的数学问题)。
人工智能指数基准
正如去年报告中强调的那样,AI技术性能的一个新兴主题是在许多基准上观察到的饱和,例如用于评估AI模型熟练程度的ImageNet。
近年来,这些基准的表现停滞不前,表明要么是AI能力停滞不前,要么是研究人员转向更复杂的研究挑战。由于饱和,2023年人工智能指数中的几个基准在今年的报告中被省略了。图2.1.17突出显示了2023年版本中包含但未在今年报告中出现的一些基准它还显示了自2022年以来这些基准的改善情况。“NA”表示没有注意到任何改善。
图2.1.18显示了2023年人工智能指数报告中精选基准的同比改善情况(以百分比为单位)。大多数基准测试在引入后很快就会看到显著的性能提升,然后改善速度减慢。在过去的几年里,许多这些基准测试几乎没有显示出任何改善。
为了应对基准测试的饱和,AI研究人员正在从传统的基准测试转向在更困难的挑战上测试AI。2024年AI Index跟踪了几个新基准的进展,包括编码、高级推理和代理行为方面的任务,这些领域在以前的报告版本中代表性不足(图2.1.19)
2.2 语言
自然语言处理(NLP)使计算机能够理解、解释、生成和转换文本。目前最先进的模型,如OpenAI的GPT-4和谷歌的双子座,能够生成流畅连贯的散文,并显示出高水平的语言理解能力(图2.2.1)。许多这样的模型现在也可以处理不同的输入形式,比如图像和音频(图2.2.2)
理解
英语语言理解挑战人工智能系统以各种方式理解英语,如阅读理解和逻辑推理。
HELM:语言模型整体评估如上所述,近年来,法学硕士在传统的英语基准上的表现超过了人类,比如SQuAD(问答)和SuperGLUE(语言理解)。这种快速的进步导致需要更全面的基准测试。
在2022年,斯坦福大学的研究人员引入了HELM(语言模型整体评估),旨在评估各种场景下的法学硕士,包括阅读理解、语言理解和数学推理HELM评估了几家领先公司的模型,如Anthropic、谷歌、Meta和OpenAI,并使用“平均胜率”来跟踪所有场景的平均表现。截至2024年1月,GPT-4以0.96的平均胜率领跑总HELM排行榜(图2.2.3);然而,不同的模型停止不同的任务类别(图2.2.4)
MMLU:大规模多任务语言理解
海量多任务语言理解(MMLU)基准评估模型在57个科目(包括人文学科、STEM和社会科学)的零射击或少射击场景中的性能(图2.2.5)。MMLU已经成为总理评估LLM能力的基准:许多最先进的模型,如GPT-4、Claude 2和Gemini,已经针对MMLU进行了评估。
2023年初,GPT-4在MMLU上取得了最先进的成绩,后来被谷歌的Gemini Ultra超越。图2.2.6显示了不同年份MMLU基准上的最高模型得分。报告的分数是整个测试集的平均值。截至2024年1月,Gemini Ultra的得分最高,为90.0%,自2022年以来提高了14.8个百分点,自2019年MMLU成立以来提高了57.6个百分点。Gemini Ultra的得分首次超过了MMLU的人类基线89.8%。
在生成任务中,测试AI模型产生流利和实用的语言响应的能力。
聊天机器人竞技场排行榜
有能力的法学硕士的崛起,使得了解哪些模型是正确的变得越来越重要受到大众的青睐。聊天机器人竞技场排行榜于2023年推出,是对公众法学硕士偏好的首批综合评估之一。排行榜允许用户查询两个匿名模型,并投票选出偏好的世代(图2.2.7)。截至2024年初,该平台已获得超过20万张选票,用户将OpenAI的GPT-4 Turbo评为最受欢迎的模型(图2.2.8)。
真实性
尽管取得了显著的成就,但法学硕士仍然容易受到事实不准确和内容幻觉的影响——创造看似真实但虚假的信息。现实世界中法学硕士产生幻觉的例子——例如在法庭案件中——凸显了密切监测法学硕士事实趋势的日益必要性。
在ACL 2022上推出的TruthfulQA是一个旨在评估法学硕士在生成问题答案时的真实性的基准。该基准包括38个类别的约800个问题,包括健康、政治和金融。许多问题都是为了挑战人们普遍持有的误解而精心设计的,这些误解通常会导致人们回答错误(图2.2.9)。尽管本文的观察结果之一是较大的模型往往不太真实,但在2024年初发布的GPT-4 (RLHF)在TruthfulQA基准上取得了迄今为止最高的性能,得分为0.6(图1)
(2.2.10)。这一分数比2021年测试的基于gpt -2的模型高出近三倍,表明法学硕士在提供真实答案方面正变得越来越好。
HaluEval
如前所述,法学硕士容易产生幻觉,鉴于他们在法律和医学等关键领域的广泛部署,这是一个令人担忧的特征。虽然现有的研究旨在了解幻觉的原因,但很少有人致力于评估法学硕士幻觉的频率,并确定他们特别脆弱的特定内容领域。
HaluEval于2023年推出,是一种旨在评估法学硕士幻觉的新基准。它包括超过35,000个样本,包括幻觉和正常,供法学硕士分析和评估(图2.2.11)。研究表明,ChatGPT在大约19.5%的回复中捏造了无法验证的信息,这些捏造跨越了语言、气候和技术等各种主题。此外,该研究还检验了当前法学硕士检测幻觉的能力。图2.2.12展示了领先的法学硕士在各种任务中识别幻觉的表现,包括问题回答、基于知识的对话和文本摘要。研究结果显示,许多法学硕士在这些任务中挣扎,强调了幻觉是一个重要的持续问题。
编码涉及生成指令,计算机可以遵循这些指令来执行任务。最近,法学硕士已经成为熟练的程序员,成为计算机科学家的宝贵助手。越来越多的证据表明,许多程序员发现AI编码助手非常有用。
2.3 编码
在许多编码任务中,AI模型面临着生成可用代码或解决计算机科学问题的挑战。
HumanEval
HumanEval是评估AI系统编码能力的基准,由OpenAI研究人员于2021年推出。它由164个具有挑战性的手写编程问题组成(图2.3.1)。GPT-4模型变体(AgentCoder)目前在HumanEval性能方面领先,得分为96.3%,比最高分提高了11.2个百分点在2022年(图2.3.2)。自2021年以来,HumanEval的表现提高了64.1个百分点。
SWE-工作台
随着AI系统编码能力的提高,在更具挑战性的任务上对模型进行基准测试变得越来越重要。2023年10月,研究人员引入了sw -bench,这是一个包含2294个软件工程问题的数据集,这些问题来自真实的GitHub问题和流行的Python存储库(图2.3.3)。sw -bench对AI编码能力提出了更严格的测试,要求系统协调各个方面的变化多个功能,与各种执行环境交互,进行复杂推理。
即使是最先进的法学硕士也面临着sw -bench的重大挑战。表现最好的模型Claude 2只解决了数据集问题的4.8%(图2.3.4)2023年,sw -bench上表现最好的车型比2022年的最佳车型高出4.3个百分点。
计算机视觉允许机器理解图像和视频,并从文本提示或其他输入创建逼真的视觉效果。这项技术被广泛应用于自动驾驶、医学成像和视频游戏开发等领域。
2.4 图像计算机视觉和图像生成
图像生成是生成与真实图像无法区分的图像的任务。今天的图像生成器非常先进,以至于大多数人很难区分ai生成的图像和人脸的实际图像(图2.4.1)。图2.4.2突出了从2022年到2024年的各种中途旅行模型变体的几代,以提示“哈利波特的超现实形象”。这一进展表明,在两年的时间里,中途旅行生成超现实图像的能力有了显著提高。2022年,该模型制作出了卡通化的、不准确的哈利波特效果图,但到2024年,它可以创造出惊人的逼真的描绘。
HEIM:文本到图像模型的整体评估
AI文本到图像系统的快速发展促使了更复杂的评估方法的发展。2023年,斯坦福大学的研究人员引入了文本到图像模型的整体评估(HEIM),这是一个基准,旨在从12个关键方面全面评估图像生成器,这些方面对现实世界的部署至关重要,如图像-文本对齐、图像质量和美学人类评估员被用来对模型进行评级,这是一个至关重要的特征,因为许多自动化指标难以准确评估图像的各个方面。
HEIM的研究结果表明,没有一个模型在所有标准中都表现出色。对于人类对图像到文本对齐的评估(评估生成的图像与输入文本的匹配程度),OpenAI的DALL-E 2得分最高(图2.4.3)。在图像质量(衡量图像是否与真实照片相似)、美学(评估视觉吸引力)和原创性(衡量新图像生成和避免侵犯版权)方面,基于Stable diffusion的Dreamlike Photoreal模型排名最高(图2.4.4)。
从文本提示创建3D几何或模型一直是AI研究人员面临的重大挑战,现有模型正在努力解决诸如多面两面问题(不准确地再生文本提示所描述的上下文)和内容漂移(不同3D视图之间的不一致)等问题。MVDream是由字节跳动和加州大学圣地亚哥分校的研究人员克服了其中的一些障碍(图2.4.5)。在定量评价中,MVDream生成的模型达到了Inception Score (IS)和CLIP分数与训练集中的分数相当,表明生成的图像(图2.4.6)。MVDream具有重大意义,特别是对在创意产业中,3D内容创作传统上是耗时且劳动密集型的。
指导遵循
在计算机视觉中,指令跟随是视觉语言模型解释与图像相关的基于文本的指令的能力。例如,AI系统可以获得各种食材的图像,并负责建议如何使用它们来准备一顿健康的饭。能够跟随指令的视觉语言模型是开发高级AI助手所必需的。
访问信息工作台
2023年,一个由行业和学术研究人员组成的团队推出了VisIT-Bench,这是一个由592个具有挑战性的视觉语言指令组成的基准,涵盖约70个指令类别,如情节分析、艺术知识和位置理解(图2.4.8)。截至2024年1月,VisIT-Bench上的领先模型是GPT-4V, GPT-4 Turbo的视觉版本,Elo得分为1349,略高于VisIT-Bench的人类参考得分(图2.4.9)。
编辑
图像编辑包括使用AI根据文本提示修改图像。这种人工智能辅助的方法在工程、工业设计和电影制作等领域有着广泛的现实应用。
编辑值
尽管文本引导的图像编辑很有前景,但很少有可靠的方法可以评估AI图像编辑器遵守编辑提示的准确性。EditVal是一个评估文本引导图像编辑的新基准,它包括超过13种编辑类型,例如在19个对象类中添加对象或更改其位置(图2.4.10)。该基准被应用于评估包括SINE和Null-text在内的八种领先的文本引导图像编辑方法。自2021年以来,在各种基准的编辑任务上的性能改进如图2.4.11所示。
强调研究:
调节输入或执行条件控制是指通过指定生成的图像必须满足的某些条件来引导图像生成器生成的输出的过程。现有的文本到图像模型往往缺乏对图像空间构成的精确控制,因此很难单独使用提示来生成布局复杂、形状多样和特定姿势的图像。通过在额外的图像上训练这些模型来微调这些模型以获得更大的构图控制在理论上是可行的,但是许多专门的数据集,比如人类姿势的数据集,都不够大,无法支持成功的训练。
2023年,斯坦福大学的研究人员推出了一种改进的新模型——控制网(ControlNet)用于大型文本到图像扩散模型的条件控制编辑(图2.4.12)。
控制网因其处理各种调节输入的能力而脱颖而出。与2022年之前发布的其他模型相比,人类评分者在质量和条件保真度方面都更喜欢控制网(图2.4.13)。控制网的引入是朝着创建高级文本到图像生成器迈出的重要一步,该生成器能够编辑图像,更准确地复制现实世界中经常遇到的复杂图像。
强调研究:
新模型可以只使用文本指令编辑3D几何图形。Instruct-NeRF2NeRF是伯克利研究人员开发的一个模型,它采用图像条件扩散模型对3D几何图形进行基于文本的迭代编辑
(图2.4.14)。这种方法有效地生成新的、经过编辑的图像,这些图像遵循文本指令,实现了比当前领先方法更大的一致性(图2.4.15)。
分割涉及到将单个图像像素分配到特定的类别(例如:人、自行车或街道)。
强调研究:
2023年,Meta研究人员启动了Segment Anything项目,该项目以Segment Anything模型(SAM)和用于图像分割的广泛SA-1B数据集为特色。SAM是值得注意的是,它是第一个可广泛推广的分割模型之一,在新任务和分布上表现良好。Segment Anything在23个分割数据集中的16个上优于RITM等领先的分割方法(图2.4.17)。评估Segment Anything的度量是平均交点除以联合(IoU)。
然后使用Meta的Segment Anything模型,与人类注释器一起创建SA-1B数据集,其中包括1100万张图像中超过10亿个分割掩码(图2.4.16)。这种规模的新分割数据集将加速未来图像分割器的训练。《Segment Anything》展示了AI模型如何与人类一起使用,以更有效地创建大型数据集,而这些数据集又可以用来训练更好的AI系统。
3D从图像重建
3D图像重建是从二维图像创建三维数字几何图形的过程。这种类型的重建可用于医学成像、机器人技术和虚拟现实。
实时融合
牛津大学研究人员开发的RealFusion是一种新方法,可以从单张图像中生成完整的物体3D模型,克服了单张图像信息不足的挑战,无法进行360度的完整重建。RealFusion利用现有的2D图像生成器生成一个对象的多个视图,然后将这些视图组装成一个完整的360度模型(图2.4.20)。与2021年最先进的方法(货架监督)相比,该技术可以在广泛的对象上产生更精确的3D重建(图2.4.21)。
AI中的推理涉及AI系统从不同形式的信息中得出逻辑有效结论的能力。AI系统越来越多地在不同的推理环境中进行测试,包括视觉(对图像进行推理)、道德(理解道德困境)和社会推理(在社会情境中导航)
2.6 推理
比较人类、GPT-4和GPT-4V在抽象和推理任务上的表现
MATH
MATH是加州大学伯克利分校的研究人员在2021年引入的12500个具有挑战性的竞赛级数学问题的数据集(图2.6.10)。当MATH首次发布时,AI系统在它上挣扎,只能解决6.9%的问题。性能有了明显的提升。在2023年,基于gpt -4的模型取得了最好的结果,成功解决了84.3%的数据集问题(图2.6.11)。
旅行者/航海家号RLAIF
本节侧重于探索LLMs的关键特性的研究,例如他们在推理中突然行为转变和自我纠正的能力。重要的是要强调这些研究,以了解日益代表AI研究前沿的法学硕士是如何运作和行为的。
斯坦福大学和伯克利大学进行的一项研究探讨了某些公开可用的法学硕士随着时间的推移的表现,并强调,事实上,它们的表现可能会有很大的变化。更具体地说,该研究比较了2023年3月和6月版本的GPT-3.5和GPT-4,并证明了在几个任务上的表现有所下降。例如,6月份版本的GPT-4比较与3月份的版本相比,生成代码的能力差了42个百分点,回答敏感问题的能力差了16个百分点,33个百分点。


 热门活动
热门活动 
 其他
其他 12-16 周二
12-16 周二
 热门报告
热门报告 










